
AI Tutorial: Creating a Custom ChatGPT That Extracts Data from Websites
You can do it too (no coding required).


Hi! Just a quick reminder that tomorrow ends our special Black Friday offer.
It’s a 50% Substack discount for the annual plan. Click here to get an annual subscription to my Substack for $47.5 per year. Although this is a special price for Black Friday, that price will remain every year as long as you remain a subscriber.
I’ve just created a GPT that extracts data from websites.
I named it ScrapeGPT. That said, it doesn’t actually go to the website and scrapes its data, or extracts the data from an HTML file as I showed you in a previous article. In this case, we’re going to use a different approach that will help us extract data from websites by just telling what data we want to get. Once we see how this works, we’re gonna quickly create a GPT to automate all this.
Just note that this method isn’t going to be appropriate for all websites out there, but it’s still powerful and easy to use. With that in mind, let’s build ScrapeGPT.
You can also follow this tutorial by watching my video below.
How this GPT works
Say, we want to scrape all the data related to “web scraping courses” from Udemy, so we go to Udemy, type “web scrapping” and get the search results.
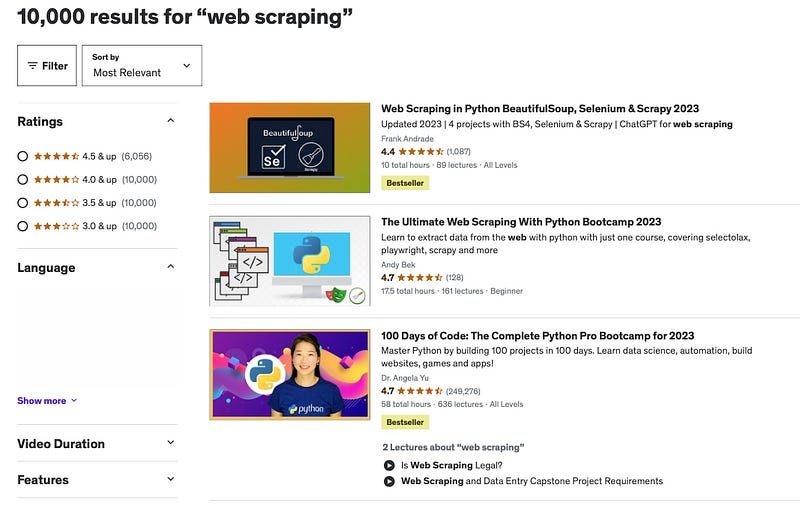
In a previous article, I showed you how to extract all this data by saving this file as HTML and then giving it to ChatGPT. That was good, but we had to provide one by one the HTML elements of the data we wanted to extract (and it sometimes could fail because some HTML files are complex)
With this new method, we only need to save the page as a PDF file and specify the data to extract. That’s it.
How to save a PDF file?
Go to the page you want to extract data from
If you’re on Chrome or Edge, click on “File” and select “Print”, on “Layout” select “Landscape” and then click on “Save” to save the page as a PDF
If you’re on Safari, click on “File” and then select “Export as PDF”
Note that on some websites Chrome exports the PDF with incomplete sections of the page. If that’s the case use Safari or another browser (Safari has never failed me so far).
Once we have the PDF, we upload it to ChatGPT and type the following prompt.
Extract data from all the items listed in the file. Here’s the data you should extract from the first item. You have to extract the same data for the rest items
Course: Web Scraping in Python BeautifulSoup, Selenium & Scrapy 2023
Instructor: Frank Andrade
Rating: 4.4
Number of ratings: 1,087
Hours: 10 total hoursYou have to put the data extracted on a table and export it to a CSV file.
- If one item has more than one price, just take the first price
- In case there’s missing data, leave that data as a null data.
In the prompt, we give as a sample the first item to extract. ChatGPT is going to extract the same data for the remaining items
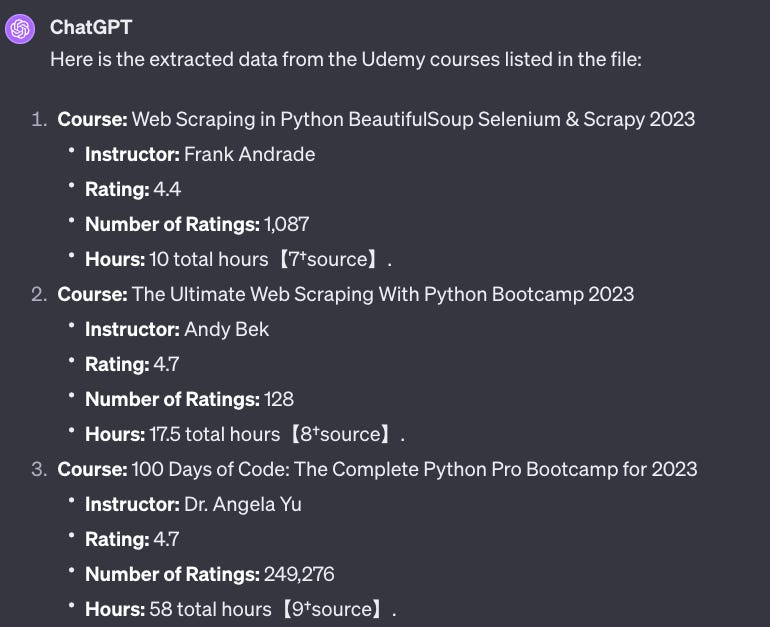
and then put it into a CSV file.
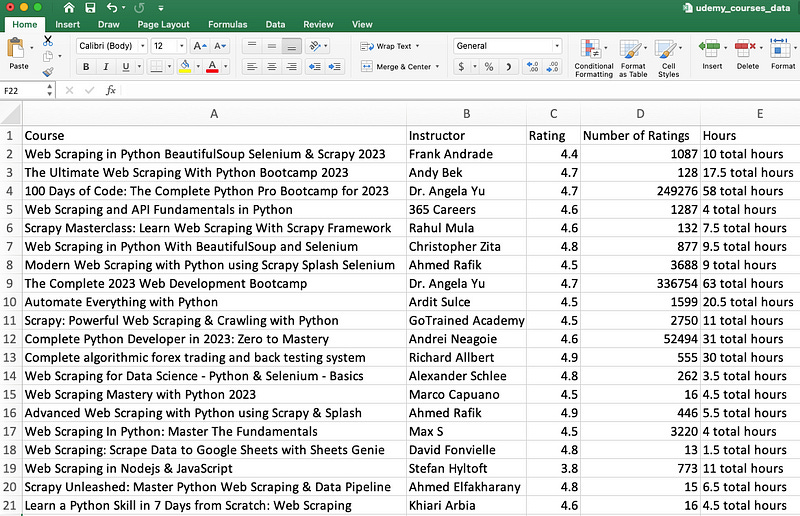
Easy, right? This approach works wonders when you want to extract data from a list of items. You can even provide the second or third page from the search result to extract more data.
Let’s build the GPT
Now let’s build the GPT, so we can automate this prompt a little bit and easily reuse it.
Open the sidebar, click on Explore, and select “Create a GPT”. Go to the “Configure” options and paste the prompt in “Instructions.”
We’re going to slightly tweak the prompt in the instructions field. Here’s the final prompt.
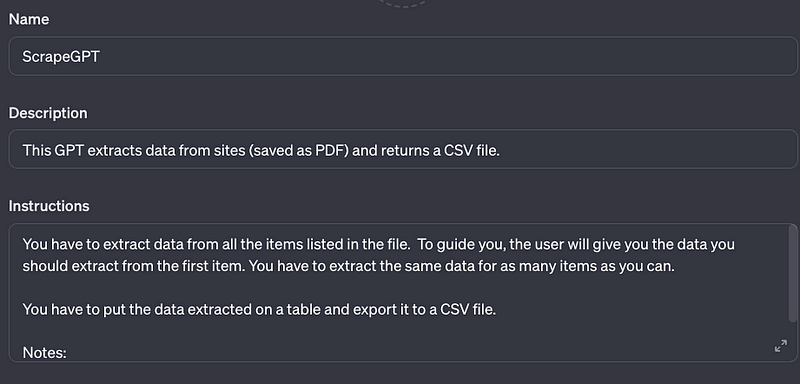
You have to extract data from all the items listed in the file. To guide you, the user will give you the data you should extract from the first item. You have to extract the same data for as many items as you can.
You have to put the data extracted on a table and export it to a CSV file.
Notes:
- If one item has more than one price, just take the first price
- In case there’s missing data, leave that data as a null data.
Some pages might have a different structure, so feel free to add more notes, in case you need it.
I’ll name the GPT as ScrapeGPT and add a quick description. I’ll only check the Code Interpreter box in capabilities.
Here’s how the GPT looks.
Now we only need to upload the PDF and type the first sample. Let’s try with Amazon now.
Here’s what I got after typing “play station” on Amazon.
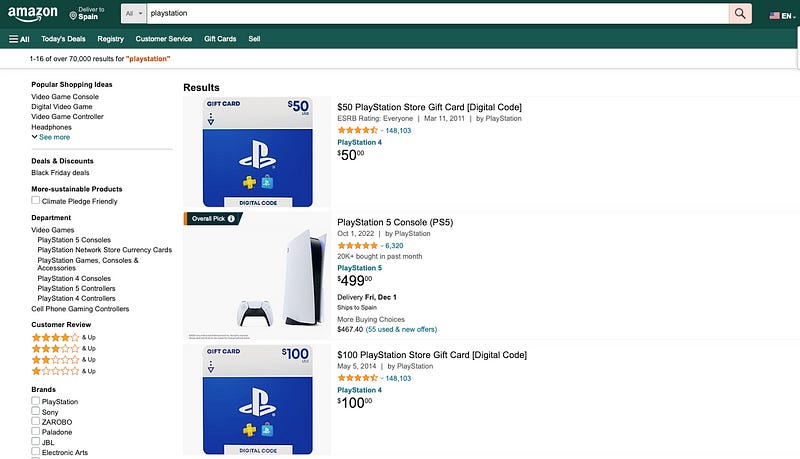
In the prompt, I’ll specify the data to extract from the first item and let ScrapeGPT get the rest of the items.
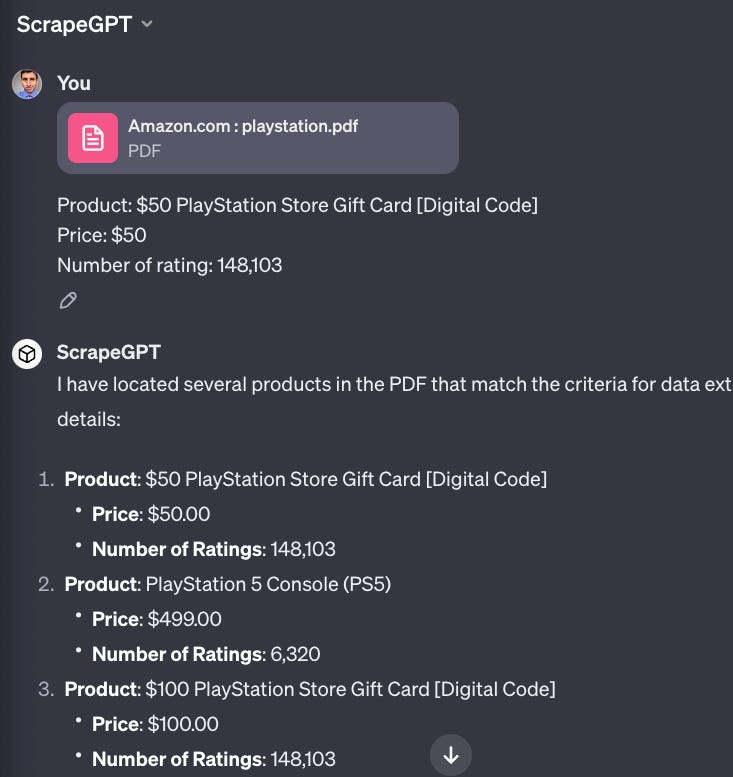
Here’s the CSV file exported.

After double-checking the CSV file, I realized there were some missing items, which was weird because when I tested the prompt without ScrapeGPT, GPT-4 successfully extracted the data from all the items.
I’ve tested different prompts in GPT-4 and GPT (created with GPT Builder) and it looks like the latter isn't as smart. When the prompt is a bit more complex, some of my GPTs even get stuck on “searching my knowledge” or “Message in conversation not found” Have you noticed this issue with your GPTs? Hopefully, OpenAI will fix this issue soon.
Anyway, today we’ve seen a simple approach to extracting data from websites with ChatGPT. I’ve made this GPT public and you can try it here. If you have any suggestions, let me know in the comment section.
Why you are not using the browse function first to get the result and then use the Data Interpreter on that. This intermediate step makes the Scraper not as usful as it can be. A first fast draft you can find here -> https://dub.sh/affiliatebot .It first scrapes the products, then make a list out of it and attaching a affiliate id (in this case a fictional)