
AI & Python #10: Automate 4 Boring Tasks in Python with 5 Lines of Code
Automation scripts with a few lines of Python code.


Think of the most boring task you’ve ever done at work. Chances are, you can automate it with Python.
You only need to open your favorite text editor and start writing code. However, you might struggle to automate some tasks more than others and end up wasting more time.
What most people don’t know, however, is that there are less-known libraries that take care of the hardest part of the automation, so you only need to write a few lines of code to get the job done.
Below are 4 tasks that you can automate with Python in 5 minutes or less. You’ll need to write 5 lines of code or so to automate each of them (seriously).
1. Sending Messages on WhatsApp
The easiest way to send messages on WhatsApp in Python is using a library called pywhatkit.
First, we need to install it, so open up a terminal and run the following command (if possible, install it in a new virtual environment).
pip install pywhatkitThe installation might take a minute, but, don’t worry, writing the script to send the message would take less.
Note: You need to log in to your WhatsApp account through WhatsApp Web before working with this library. If you’re not logged in, you won’t be able to send messages with pywhatkit. Also, I don’t recommend you to use this library in case you need to send a message that needs to remain private.
Now it’s time to send the message. We can send a message to a WhatsApp contact using the code below.
import pywhatkit# syntax: phone number with country code, message, hour and minutes
pywhatkit.sendwhatmsg('+1xxxxxxxx', 'Message 1', 18, 52)Keep in mind that the “18” and “52” are the hour/minute your message is being scheduled, so try to set it within 1 or 2 minutes to see the results faster.
Once you run the code, you’ll get this message:
In 5 seconds, web.WhatsApp.com will open, and after 15 seconds, a message will be delivered by Whatsapp.
2. Multiple Folder Creation
One of the dullest tasks I ever had at work was creating folders for each day/month of the year. These folders would contain important files, so they needed to be properly organized.
Something like this.
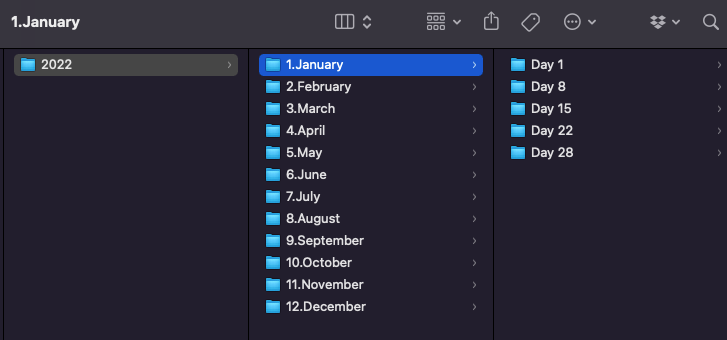
Although that looks simple, that might stop you from doing other productive tasks. Fortunately, we can automate folder creation using pathlib. I believe this library comes with Python, but if you don’t have it, just install it with pip.
The tricky part here is obtaining the name of the months. What some people do is create a list and manually type the names of the months from January to December.
That’s OK, but we could easily get the names of the month using the calendar module.
import calendarmonth_names = list(calendar.month_name[1:])
print(month_names)Then, we have to manually write the days we want in a list (if you have to create folders for day 1 to day 31, save time creating them with a list comprehension)
days = ['Day 1', 'Day 8', 'Day 15', 'Day 22', 'Day 28']Now, we can loop through each month/day of the year using the code below.
from pathlib import Path
import calendar
month_names = list(calendar.month_name[1:])
days = ['Day 1', 'Day 8', 'Day 15', 'Day 22', 'Day 28']
for i, month in enumerate(month_names):
for day in days:
Path(f'2022/{i+1}.{month}/{day}').mkdir(parents=True, exist_ok=True)After running the code, a new “2022” folder will be created in your working directory. Inside you’ll see folders for each month and day of the year as shown in the screenshot above.
3. Extract Tables from PDFs
There’s a library called camelot that helps you extract tables from PDFs. It doesn’t always work smoothly, but there are ways to customize the extraction.
Before you install camelot, you might need to install libraries such as tk and Ghostscript (check the documentation for more details)
Once you have all the requirements, you can install camelot.
# pip
pip install camelot-py# conda
conda install -c conda-forge camelot-pyFor this simple demonstration, I’m going to use this PDF available here that is named “foo.pdf” Download the file and save it in your working directory.
To read this PDF file, we can use the .read_pdf method
import camelottables = camelot.read_pdf('foo.pdf', pages='1', flavor='lattice')
print(tables)If you print this, you’ll get the number of tables on page #1. In this case, there’s only one table. Also, keep in mind that you can customize the extraction with the flavor parameter. It’s set to lattice by default but you can set it to stream.
Now to extract the table from the PDF, we use the .export method, and then we can either print it as a dataframe or export it to a CSV file.
tables.export('foo.csv', f='csv', compress=True)tables[0].to_csv('foo.csv') # to a csv file
print(tables[0].df) # to a dfGreat! If you export it to CSV, the file should be in your working directory.
4. Extract Tables from Websites
Most people don’t know that we can easily extract tables from websites using only Pandas (in case you don’t have Pandas, install it with pip: pip install pandas)
Say you want to extract tables from Wikipedia. You can do that in seconds using the .read_html method. The code below helps me extract all the tables listed in this Simpsons post on Wikipedia.
import pandas as pdsimpsons = pd.read_html('https://en.wikipedia.org/wiki/List_of_The_Simpsons_episodes_(seasons_1%E2%80%9320)')Now I have 20 tables stored in the simpsons list. We can select the second table by indexing:
# getting the first 5 rows of the table "Season 1" (second table)
simpsons[1].head()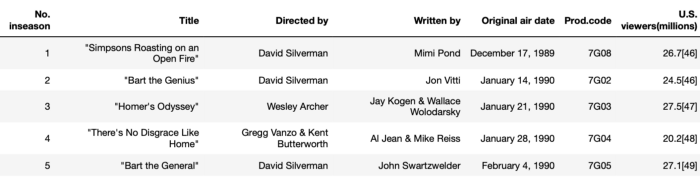
That’s it! You‘ve just automated 5 boring tasks in record time using Python.