
AI & Python #18: AI Enthusiasts Should Move from Excel to Python. Here's How
A guide on Python libraries Pandas and Numpy.


We’re continuing with out Behind AI series. I’ve just added a tab to the Artificial Corner site where you can follow all the editions of this series. Click here to see it.
As someone who has been working with Excel for many years, I know that the idea of learning things you can already do in Excel/VBA in a completely new environment like Python doesn’t sound so exciting.
However, in 2024 there are many reasons why Excel users should learn Python. Here are the top two reasons:
Python is officially being integrated into Excel
Python is the language of choice for learning AI and Machine Learning
I created a useful and simple guide I wish I had when I switched from Excel to Python. In this guide, we’ll use Python’s Pandas and Numpy libraries to replace Excel functions (IF, SUM, VLOOKUP, etc), pivot tables, and charts.
In this guide, we’ll work with Jupyter Notebook, which is a code editor used in Python for data analysis. You can watch my video tutorial on how to install Python + Jupyter Notebook via Anaconda.
The Dataset
In this guide, we’ll use an Excel file that has a .csv format, which is typically used when working with datasets. The dataset consists of the marks secured by students in various subjects and will help us easily switch from Excel spreadsheets to Python’s dataframes. You can download this data on Kaggle or on my Github (check the datasets folder).
To start with this guide, let’s import the Pandas and Numpy libraries.
import pandas as pd
import numpy as npNote: If you don’t have those libraries installed in Python, you can easily install them by writing pip install pandas and pip install numpy on your terminal or command prompt.
With this, we can take a first look at the data. To do so, we use pd.read_csv(). Make sure that the CSV and your Python script are located in the same place (same path).
df_excel = pd.read_csv('StudentsPerformance.csv')
df_excelOnce we read this CSV file, we give it a name. In this case, I named it df_excel. df stands for dataframe and it’s the typical name given after reading a CSV file. After running the code below, we obtain the following output.
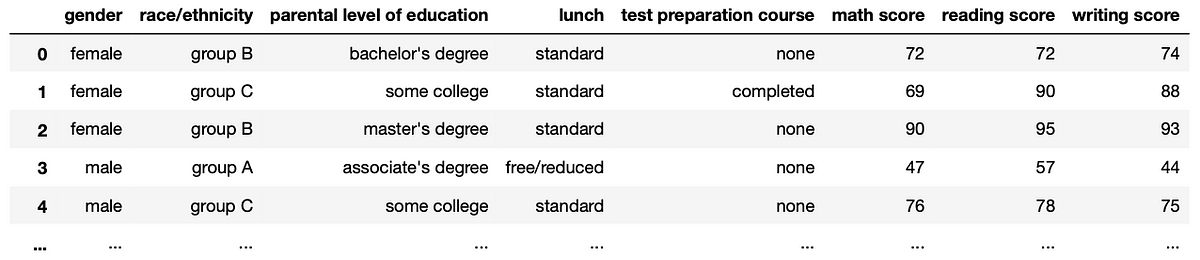
This looks similar to an Excel spreadsheet, but in this format, it’ll be easier to wrangle the data. Now I’ll show you in Python how to do some common functions you probably used in Excel.
Sum, Average, Max, Min, Count
Excel’s popular functions can be easily replaced with Pandas methods. Let’s take a look.
Columns (e.g. sum a column)
If we want to get most of the functions listed above, we use the .describe() method.
df_excel.describe()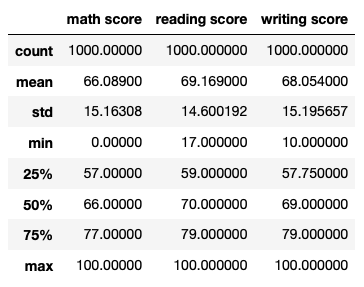
As you can see, with this we get the count, mean, max, and min values of all numerical columns.
However, if we want to select a specific row, we first select with square brackets [ ] and then use the method we need (.sum(), .mean(), etc.). For example, let’s calculate the average of math scores.
In [1]: df_excel['math score'].mean()
Out [1]: 66.089These are some of the other methods you can use.
df_excel['math score'].mean()
df_excel['math score'].max()
df_excel['math score'].min()
df_excel['math score'].count()Rows (e.g. sum a row)
Now let’s say we want to calculate the average of the 3 marks (math, reading, and writing). Those values are within different columns, so we have 2 options. We can either sum each column
df_excel['average'] = (df_excel['math score'] + df_excel['reading score'] + df_excel['writing score'])/3Or use the method we used before to sum values within a column, but in this case, we add axis=1
df_excel['average'] = df_excel.mean(axis=1)We also added a new column [‘average’] when calculating the average. We’ll use this new column for the next section (IF).
Keep in mind that in this example we could use the second option because the only numerical values are within the desired columns ( (math, reading, and writing scores). If there was an additional column we didn’t want to consider in the sum, we should only use the first option.
In case we want to count the number of specific data within a column, we can use the .value_counts() method
In [2]: df_excel['gender'].value_counts()
Out [2]:
female 518
male 482IF
We can easily replace Excel’s IF function by using Numpy.
Replace IF with np.where
Let’s imagine we want to know whether a student has passed or failed an exam and create a new column with that information. We can easily do that with the following code.
df_excel['pass/fail'] = np.where(df_excel['average'] > 70, 'Pass', 'Fail')As you can see np.where() needs 3 arguments — the condition, the value if the condition is True, and the value if the condition is False.
Replace nested IF with np.select
Let’s imagine we want to give grades from A to F based on the scores obtained. In this case, we have more than 2 values, so we use np.select()
np.select() needs to arguments — a list of conditions and a list of values. A list in Python is represented by the square brackets [ ]
conditions = [
(df_excel['average']>=90),
(df_excel['average']>=80) & (df_excel['average']<90),
(df_excel['average']>=70) & (df_excel['average']<80),
(df_excel['average']>=60) & (df_excel['average']<70),
(df_excel['average']>=50) & (df_excel['average']<60),
(df_excel['average']<50),
]values = ['A', 'B', 'C', 'D', 'E', 'F']Keep in mind that each condition should be within parenthesis. Now we use the .select() method and assign it to a new [‘grades’] column.
df_excel['grades'] = np.select(conditions, values)Now the first 5 rows of the output should look like this.
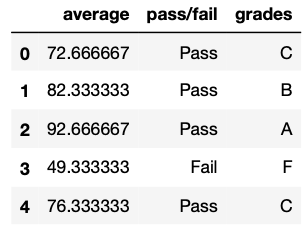
We picked these 3 columns with double square brackets df_excel[[‘average’, ‘pass/fail’, ‘grades’]] and the first 5 rows can be displayed with the .head() method.
SumIf, CountIf, AverageIf
To sum, count, or calculate the average based on a condition, in Python, we first filter out values and then make the calculation.
One condition (select a column with square brackets [ ] )
Let’s imagine we want to sum the scores for only the female gender. To do so, first, we write the condition df_excel[‘gender’] == ‘female’ and then. we select that condition inside the df_excel frame by using square brackets [ ]
df_female = df_excel[df_excel['gender'] == 'female']We selected only the female gender and placed it in a dataframe called df_female. Now we can perform any calculation we saw in the “Sum, Average, Max, Min, Count” section.
Two or more conditions (select columns and use & or |)
If we have two or more conditions, the code will look similar to the one above, but with some changes. Let’s imagine we want to calculate the score of females within Group B (‘race/ethnicity’)
df_sumifs = df_excel[(df_excel['gender'] == 'female') & (df_excel['race/ethnicity'] == 'group B')]Since there are 2 conditions we could use & | that represents and/or respectively. Keep in mind that each condition should be within parenthesis.
Now let’s sum the scores.
df_sumifs = df_sumifs.assign(sumifs = df_sumifs['math score'] + df_sumifs['reading score'] + df_sumifs['writing score'])In this case, I used the .assign() method to show you another way to create a new column while doing calculations.
Basic Data Cleaning
We’re going to check a few methods used for data cleaning. In case you want to know all the methods used for cleaning data, check the complete guide I wrote on how to clean and prepare data in Python.
We’ll continue using the df_excel frame we defined before.
Change the case of text with .str.lower, .str.upper or .str.title
To access the strings contained in a column, we use .str Then we can change the case of text with the following
df_excel['gender'].str.title()
df_excel['gender'].str.upper()
df_excel['gender'].str.title()To save the values we can overwrite a column like in the code below.
df_excel['gender'] = df_excel['gender'].str.title()But in this case, we’ll leave the values as it is.
Extract text in a column with .str.extract
We can easily extract text from a column with .str.extract. In addition to that, if we want to extract specific patterns of a text we can use regular expressions.
Let’s imagine we want to extract only the words in upper case within the column ‘race/ethnicity’ (e.g., “B” from “Group B”). To do so, we write the following code.
df_excel['race/ethnicity'].str.extract(r'([A-Z])')In this case, we used the regular expression r'([A-Z])’ where [A-Z] indicate words in upper case, while the parenthesis () is necessary to pick the desired pattern. Regular expressions might look intimidating, but they’re simpler than you think.
Identify whether a cell is empty with the .isnull method
To replace Excel’s COUNTA, in Python we can use .isnull() to find empty values.
df_excel[df_excel['gender'].isnull()]In this case, there are no empty values so the result will be an empty dataframe.
Vlookup
To find elements as Vlookup does in Excel, we’re going to use .loc[], .merge() or .concat() based on the problem we want to solve.
Only for these examples, we’re going to work with 2 Excel spreadsheets. The first is the same “StudentsPerformance” we’ve been working with so far, while the second is a CSV file named “LanguageScore” that I created with random id and language score values (you can find this file on my Github). Let’s read both files with pd.read_csv() as we did before.
excel_1 = 'StudentsPerformance.csv'
excel_2 = 'LanguageScore.csv'df_excel_1 = pd.read_csv(excel_1)
df_excel_2 = pd.read_csv(excel_2)Now we’re going to create an id column on df_excel_1 so it has a column in common with df_excel_2. To do so, we run the following code.
df_excel_1 = df_excel_1.reset_index()
df_excel_1 = df_excel_1.rename(columns={'index':'id'})As you can see, I made an id column based on the index. reset_index() gets rid of the index by adding it as a column. You can drop the index doing .reset_index(drop=True) but in this case, I’ll rename this new index column by using the .rename() method. With this, we have a new id column.
Find an element with .loc[ ]
Finding an element using Pandas is as easy as writing .loc[] . Inside [] we have to include the row and column label. Ler’s find the information related to row 100.
In [3]: df_excel_1.loc[100, ]
Out [3]:id 100
gender male
race/ethnicity group B
parental level of education some college
lunch standard
test preparation course none
math score 79
reading score 67
writing score 67We can also set conditions. For example, we want to get the math score for the student with id equal to 100.
In [3]: df_excel_1.loc[df_excel_1['id']==100, 'math score']
Out [3]:
100 79
Name: math score, dtype: int64This means that the student with id 100 got score 79 in math.
Merge two tables with pd.merge or pd.concat
Let’s imagine you want to add the language score of all students who gave the exam. In this case, we use pd.merge(). This requires that 2 tables have 1 common column. In this case, this column is the id column.
df_excel_3 = pd.merge(df_excel_1, df_excel_2, on='id', how='left')
df_excel_3['language score'].fillna('0', inplace=True)Above you can see that another argument is needed (how). This indicates how the merge is performed. Left and right will havedf_excel_1 and df_excel_2 as a reference for the final result, while inner will only give the common data inside the id column.
You can also use pd.concat() for the same purposes, but you have to set the id as index before concatenating frames and include the frames as lists (within brackets [])
df_excel_3 = pd.concat(
[df_excel_1.set_index('id'), df_excel_2.set_index('id')], axis=1
)
df_excel_3['language score'].fillna('0', inplace=True)
df_excel_3All the values that don’t match will receive a NaN, but we can replace it with any value by using the.fillna() method.
Pivot Table
Use the .pivot_table method
The Pandas’ pivot_table method works similarly to the one you find in Excel.
Let’s imagine we want to obtain the math and writing score of all the groups inside the race/ethnicity column.
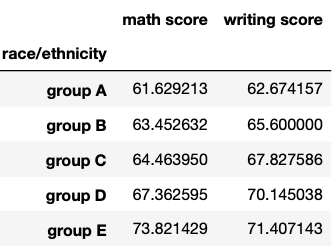
df_excel = pd.read_csv('StudentsPerformance.csv')df_pivot = df_excel.pivot_table(index='race/ethnicity', values=['math score', 'writing score'], aggfunc='mean')
df_pivotThe index argument will group the ‘race/ethnicity’ column, while the values argument will take the numerical values to show. Finally, the calculations are made by the aggfunc. In this case, we pick the mean. As a result, we obtain the following pivot table.
Replace Excel Graphs with Python’s Matplotlib or Seaborn
Python contains different libraries to make visualizations as good as those Excel offers.
Let’s make a simple barplot based on the results of df_pivot we created above. First, we import matplotlib and then we use plt.bar()
import matplotlib.pyplot as plt
df_plot = df_pivot.reset_index()
plt.bar(df_plot['race/ethnicity'], df_plot['math score'])
plt.show()The first argument of plt.bar() is the label and the second is the numeric value. Then we display the results with plt.show()
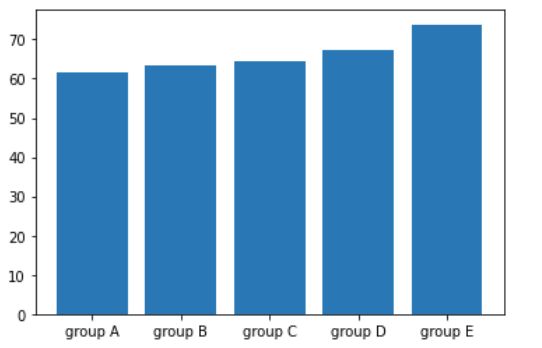
There are many things you can do in a Python plot such as adding labels to the graph, titles, customizing the size of the figure and colors, but that’s a whole new topic.
That’s it! In this guide, we did a quick overview of concepts such as data cleaning, visualization, and regular expressions. In the coming guides, we’ll dive deeper into these concepts.