
AI & Python #19: How to Create Beautiful Visualizations in Python
Customize Matplotlib & Seaborn and forget those ugly blue bars forever.

In the previous article in our series, we did an overview of Python for data analysis. Now we’ll focus on one of my favorite tasks: data visualization!
Picture this: You’re in the middle of a project and suddenly you need to make a plot to analyze the data or present the insights found. You don’t have too much time, but you definitely don’t want to create a plot that looks like this.

However you also don’t want to get too technical and waste more time on something that isn’t the main goal of your project, so what should you do?
I can’t tell how many times that happened to me in the past, but by using Matplotlib & Seaborn conveniently, I came up with a simple, yet powerful way to create nice-looking and readable visualizations in Python. Forget those blue bar plots and pie charts with tiny labels, in this article, I’ll show you how to give them a better appearance without getting too technical and wasting a lot of time.
Content of this Guide
1. Graph style and Font size
2. Customization of Plots
- Color Palettes
- Figure size, figure appearance, title, and axes labels
3. The Dataset
4. Bar Plot
5. Histogram
6. Boxplot
7. Scatterplot
8. Piechart + Subplots
- Single Piechart
- Piechart side by side (subplots)
9. Line PlotResources for this guide:
👉 Dataset: Kaggle, GitHub
👉 Script: GitHub
Globally Setting: Graph style and Font size
One of the things that gave me more headaches was setting font sizes in plots individually. That’s why it’s better to globally set them first before we start making plots. First, let’s import the necessary libraries we’ll use in this article.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pdNote: If you don’t have those libraries installed in Python, you can easily install them by writing pip install name_of_library on your terminal or command prompt for each library you wish to install (e.g. pip install matplotlib)
Now we can easily globally set the graph style and font size with the following code.
sns.set_style('darkgrid') # darkgrid, white grid, dark, white and ticksplt.rc('axes', titlesize=18) # fontsize of the axes title
plt.rc('axes', labelsize=14) # fontsize of the x and y labels
plt.rc('xtick', labelsize=13) # fontsize of the tick labels
plt.rc('ytick', labelsize=13) # fontsize of the tick labels
plt.rc('legend', fontsize=13) # legend fontsize
plt.rc('font', size=13) # controls default text sizesFirst, we use sns.set_style() to set the graph style. This will make Matplotlib and Seaborn graphs look better by default. Then we use plt.rc() to customize the font size of the text displayed in the plots. My personal choice is 18 for the title, 14 for the text in the axes, and 13 for the rest. Feel free to edit them as you want.
That’s it! You only need to do this once to get adequate font sizes and a nice graph style.
Customization of Plots
Color Palettes
Matplotlib colors by default are ugly but we can easily make them prettier by using Seaborn palettes. These are some of the palettes Seaborn has and we’ll use in this article.
sns.color_palette(‘deep’)

sns.color_palette(‘pastel’)

sns.color_palette(‘Set2’)

These palettes have the form of a list, so instead of using the classical ‘b’ to obtain the blue color, you can extract the color from these palettes by doing sns.color_palette('deep')[0]. If you execute this code, you’ll obtain an RGB code like this (0.298, 0.447, 0.690), which is accepted in the color parameter in Matplotlib’s plots. We’ll check this better when creating the plots.
In the seaborn documentation, you can find a list of palettes available. Choose the one you like to start making nice-looking graphs.
Figure size, figure appearance, title, and axes labels
When creating plots most of the time we’ll need to make some tweaks, so anyone would easily understand our visualizations. The following methods will be used repeatedly throughout the plots presented in this article, so let’s get used to them.
How to adjust figure size? To adjust the figure size we use plt.figure(figsize). We’ll also use tight_layout=True to clean up the padding in a plot or between subplots.
plt.figure(figsize=(8,4), tight_layout=True)How to edit the figure appearance? Some of the basic tweaks we’ll make to the plot are the color and the linewidth. They are included as extra parameters when plotting.
# matplotlib
plt.hist(..., color=sns.color_palette('Set2')[2], linewidth=2)# seaborn
ax = sns.histplot(..., palette='Set2', linewidth=2) # seaborn will have either the color or palette parameters available (it depends on the plot)How to add subplots (side-by-side plots)? We’ll need plt.subplots() to make side-by-side plots.
#subplots
fig, ax = plt.subplots(nrows=1,ncols=2, figsize=(12, 5), tight_layout=True)After creating subplots, we’ll use either one-dimensional ax[0] or two-dimensional axes ax[0][0]
How to add label and title to the plot? Adding labels to axes and setting title names is similar between Matplotlib plt.xlabel() and Seaborn ax.set_xlabel(), but I prefer to use the ax.set() variant in Seaborn because it takes care of most parameters in one line.
# matplotlib
plt.xlabel('Nationality')
plt.ylabel('Average Rating')
plt.title('Barplot')# seaborn
ax.set(title='Barplot', xlabel='Nationality', ylabel='Average Rating')The Dataset
To make meaningful graphs, we need to use a dataset. To make things simple, I chose a clean dataset available in Kaggle that you can also find on my Github. This is a Fifa players dataset that will help us compare non-traditional football nations like the USA and Canada with big football nations such as England, Brazil, and Argentina. Hopefully, at the end of this article, we’ll better understand what makes football different in those countries.
For the following sections, we’ll work with a dataframe named df_country that will include only the countries in question. The code below will take care of that.
df_fifa21 = pd.read_csv('players_20.csv')
country = ['United States', 'Canada', 'England', 'Brazil', 'Argentina']
df_country = df_fifa21[df_fifa21[‘nationality’].isin(country)]Now let’s create nice-looking visualizations!
Bar Plot
Bar plots can be easily created with both MatplotLib and Seaborn with some slight differences. A barplot will display categorical data with rectangular bars with heights or lengths proportional to the values that they represent. It’ll be interesting to see the average rating of football player by nationality
The code below shows the extra preprocessing necessary only for this plot.
# Preprocessing
barplot = df_country.groupby(['nationality'], as_index=False).mean()[['nationality', 'overall']]The output looks like this:
nationality overall
Argentina 69.118510
Brazil 71.143894
Canada 62.855072
England 63.253293
United States 64.538682Bar Plot in MatplotLib with plt.bar()
MatplotLib’s plt.bar() needs two arguments — the name of the categorical variable (nationality) and their lengths (overall ratings).
plt.figure(figsize=(8,4), tight_layout=True)
colors = sns.color_palette('pastel')plt.bar(barplot['nationality'], barplot['overall'], color=colors[:5])plt.xlabel('Nationality')
plt.ylabel('Average Rating')
plt.title('Barplot')
plt.show()As we mentioned before, to make bar plots more appealing we’ll use Seaborn color palette. In this case, we used the pastel palette.
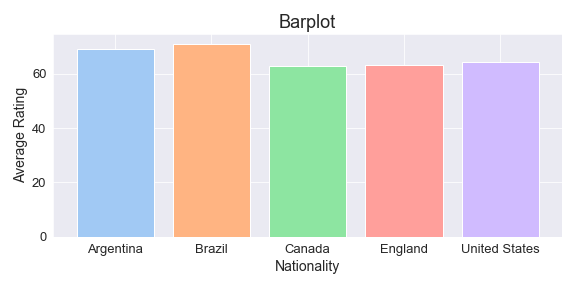
Apparently, there’s no big difference between the rating of an average player from Canada, the USA, and England. However, average players don’t make it to the national teams, but only the top players in each country do it, so if we get the average rating of the top 20 players, the plot would change. Let’s check this with seaborn.
Bar Plot in Seaborn with sns.barplot()
To get the top 20 players of each country we need to do some preprocessing
# preprocessing
new_df = pd.concat(
[df_country[df_country['nationality']=='Argentina'][:20],
df_country[df_country['nationality']=='Brazil'][:20],
df_country[df_country['nationality']=='England'][:20],
df_country[df_country['nationality']=='Canada'][:20],
df_country[df_country['nationality']=='United States'][:20]]
)barplot = new_df.groupby(['nationality'], as_index=False).mean()[['nationality', 'overall']]Now the data is ready to be plotted. We’ll use sns.barplot() to do so.
plt.figure(figsize=(8,4), tight_layout=True)
ax = sns.barplot(x=barplot['nationality'], y=barplot['overall'], palette='pastel', ci=None)
ax.set(title='Barplot', xlabel='Nationality', ylabel='Average Rating')
plt.show()
The difference in ratings between top players is evident. This reveals why the USA and Canada aren’t big football nations yet, but that’s not everything let’s dig deeper.
Barplot grouped by “n” variables
Now let’s see how many players play in the top football leagues. To do so, we need to group the data by nationality and league (we’ll leave out the Premier League since most England players play in this competition)
# Preprocessing
barplot = df_country[df_country['league_name'].isin(['Spain Primera Division', 'Italian Serie A', 'German 1. Bundesliga'])]
barplot = barplot.groupby(['nationality', 'league_name'], as_index=False).count()Now that the data is ready, we could plot it with Matplolib or Seaborn; however, to keep things simple and avoid writing more lines of code we’ll use Seaborn. Data grouped by “n” variables can be easily plotted by adding the hue=‘’ parameter.
plt.figure(figsize=(12, 6), tight_layout=True)
ax = sns.barplot(x=barplot['nationality'], y=barplot['sofifa_id'], hue=barplot['league_name'], palette='pastel')
ax.set(title='Nº of Players outside of domestic league' ,xlabel='Country', ylabel='Count')
ax.legend(title='League', title_fontsize='13', loc='upper right')
plt.show()We took care of the legend options individually with ax.legend() and obtained the following plot.

As we can see, most Argentine and Brazilian footballers play in the top leagues while Canadians and Americans don’t. Players in top leagues make an impact on the national team's success in competitions, so this explains why Brazil and Argentina are big football nations.
Histogram
A histogram represents the distribution of numerical data. Let’s look at the height distribution of football players and analyze its relevance in this sport.
Histograms with plt.hist() or sns.histplot()
MatplotLib’s plt.hist() and Seaborn’s sns.histplot()work the same. Both need two arguments — the name of the numerical variable (height) and the number or list of bins. In this case, we made a list of bins called bins that will be displayed on the x-axis.
plt.figure(figsize=(10,6), tight_layout=True)
bins = [160, 165, 170, 175, 180, 185, 190, 195, 200]
# matplotlib
plt.hist(df_country['height_cm'], bins=bins, color=sns.color_palette('Set2')[2], linewidth=2)
plt.title('Histogram')
plt.xlabel('Height (cm)')
plt.ylabel('Count')
# seaborn
ax = sns.histplot(data=df_country, x='height_cm', bins=bins, color=sns.color_palette('Set2')[2], linewidth=2)
ax.set(title='Histogram', xlabel='Height (cm)', ylabel='Count')
plt.show()
The histogram reveals that most players’ height is between 175-185 cm, so it seems that being taller than 185cm isn’t so important in football. Let’s check the distribution of height in players from different nations with boxplots.
Boxplot
Boxplots display the distribution of data based on the minimum value, first quartile (Q1), median, third quartile (Q3), and maximum value. In this case, we’ll make a boxplot showing the height distribution in players from the 5 countries.
Boxplots of multiple categorical variables can be plotted on Matplotlib but it needs some extra preprocessing, so to keep things simple we’ll use Seaborn’s sns.boxplot(). When making boxplots with multiple categorical variables we need two arguments — the name of the categorical variable (nationality) and the name of the numerical variable (height_cm)
plt.figure(figsize=(10,6), tight_layout=True)
ax = sns.boxplot(data=df_country, x='nationality', y='height_cm', palette='Set2', linewidth=2.5)
ax.set(title='Boxplot', xlabel='', ylabel='Height (cm)')
plt.show()
Now the boxplot reveals that a national team doesn’t need many tall football players to succeed in competitions since the median of Argentina and Brazil is lower than in the rest of the countries. Argentina even presents the shortest football players among the five countries represented by the long bottom whisker.
Scatterplot
A scatter plot displays and shows the relation between two numerical variables in a dataset. In this case, we’ll see the relationship between the height and weight of players.
plt.figure(figsize=(10,6), tight_layout=True)
ax = sns.scatterplot(data=df_country, x='height_cm', y='weight_kg', hue='nationality', palette='Set2', s=60)
ax.set(xlabel='Height (cm)', ylabel='Weight (kg)')
ax.legend(title='Country', title_fontsize = 12)
plt.show()In this plot, we added the sto control the dot size and also hue to differentiate the nationality

From this scatterplot, we can see that weight and height distribution fit a simple linear regression.
Piechart + Subplots
Single Piechart
We’re going to make a piechart that displays the value of players. In this example, we’ll pick the most valuable player in the USMNT (Pullisic) and see how valuable he is in his club.
# Preprocessing
piechart = df_fifa21[df_fifa21['club_name']=='Chelsea']
piechart = piechart.sort_values('value_eur', ascending=False)[['short_name', 'value_eur']]
piechart = piechart[:11]Now that the data is ready we can make a piechart with Matplolib’s plt.pie() Apart from the parameters we usually add, we’ll also consider autopct to round the numbers, explode to highlight a specific player, pctdistance to adjust the distance of the labels and shadow=True to give the chart a solid appearance.
colors = sns.color_palette('pastel')
plt.figure(figsize=(7, 6), tight_layout=True)
explode_list = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.2]
plt.pie(piechart['value_eur'], labels=piechart['short_name'], autopct='%.0f %%', explode=explode_list, pctdistance=.7,
colors=colors, shadow=True)
plt.title('Chelsea', weight='bold')
plt.show()
The piechart shows that Pullisic isn’t the most valuable player in his club, but at least he’s in the top 11.
Piechart side by side (subplots)
Now let’s plot 2 piecharts side by side to see the impact of this player on his club and national team. To do so, we’ll use plt.subplots(nrows, ncols). Here the rows and the columns determine the number of plots we’re going to create so nrow=1 and ncols=2 means 1 plot per column (2 in total).
#subplots
fig, ax = plt.subplots(1,2, figsize=(12, 5), tight_layout=True)Also, we need to create a second piechart frame piechart2, apart from the piechart we created before.
# Preprocessing
piechart2 = df_fifa21[df_fifa21['nationality']=='United States']
piechart2 = piechart2[:10].sort_values('value_eur')[['short_name', 'value_eur']]Now we can plot the 2 piecharts side by side.
colors = sns.color_palette('pastel')
explode_list = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.2]
ax[0].pie(piechart['value_eur'], labels=piechart['short_name'], autopct='%.0f %%', explode=explode_list, pctdistance=.7,
colors=colors, shadow=True)
ax[0].set_title('Chelsea', weight='bold')
explode_list = [0.1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
ax[1].pie(piechart2['value_eur'], labels=piechart2['short_name'], autopct='%.0f %%', explode=explode_list, pctdistance=.7,
colors=colors, shadow=True)
ax[1].set_title('USA', weight='bold')
plt.show()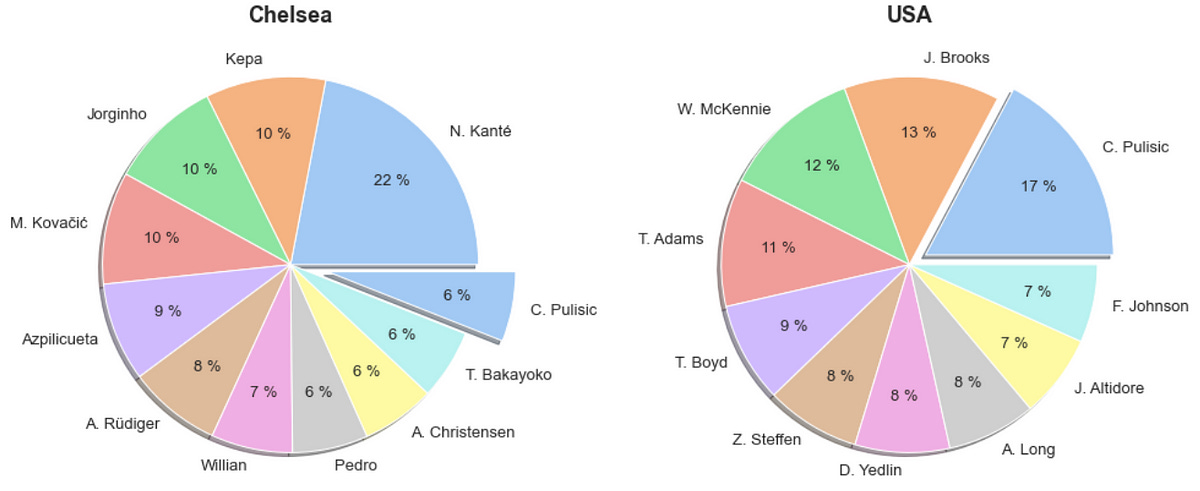
Now we can verify that Pullisic is by far the most valuable American player, but in his club, there are other skillful players ahead.
Line Plot
We’ll plot the ratings of the top football players to see how the rating evolved over the past 5 years. To do so, we have to read the Fifa dataset from 2017 and wrangle the data.
# preprocessing
df_fifa21 = pd.read_csv('players_21.csv')
df_fifa20 = pd.read_csv('players_20.csv')
df_fifa19 = pd.read_csv('players_19.csv')
df_fifa18 = pd.read_csv('players_18.csv')
df_fifa17 = pd.read_csv('players_17.csv')
frames = [df_fifa17, df_fifa18, df_fifa19, df_fifa20, df_fifa21]
for i, frame in enumerate(frames):
frame['year'] = 2017 + i
lineplot = pd.concat(frames)[['short_name', 'overall', 'year']]
list_players = ['L. Messi', 'Cristiano Ronaldo', 'K. De Bruyne', 'K. Mbappé', 'V. van Dijk']
lineplot = lineplot[lineplot['short_name'].isin(list_players)]
lineplot = lineplot.pivot(index='short_name', columns='year' ,values='overall').T
lineplot.reset_index(inplace=True)
lineplot = lineplot.set_index('year')The code above gives a dataset ready to be plotted.

Line Plot in Matplolib with plt.plot()
Making a line plot it’s as easy as typing plt.plot() on Matplotlib, but we’ll do some simple customization to make it look better.
plt.figure(figsize=(10,6), tight_layout=True)
#plotting
plt.plot(lineplot, 'o-', linewidth=2)
#customization
plt.xticks([2017, 2018, 2019, 2020, 2021])
plt.xlabel('Years')
plt.ylabel('Ratings')
plt.title('Rating troughtout the years')
plt.legend(title='Players', title_fontsize = 13, labels=['L. Messi', 'Cristiano Ronaldo', 'K. De Bruyne', 'V. van Dijk', 'K. Mbappé'])
plt.show()With the code above, we generate the following graph.
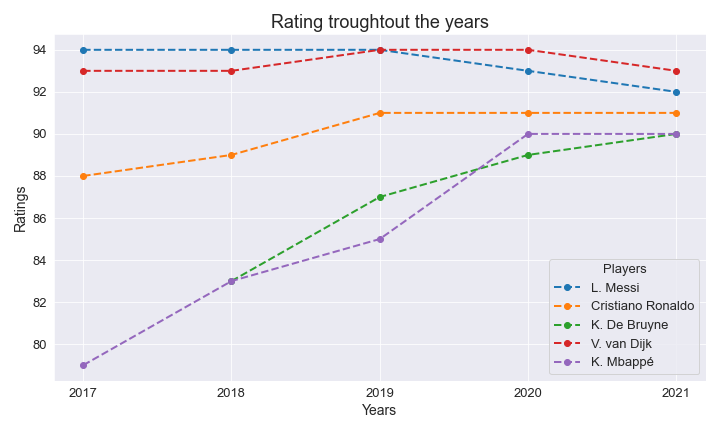
Line Plot in Seaborn with sns.lineplot()
We can also easily make this plot with seaborn.
plt.figure(figsize=(10, 5))
ax = sns.lineplot(data=lineplot, linewidth=2.5)
ax.set(xlabel='Year', ylabel='Ratings', title='Rating troughtout the years', xticks=[2017, 2018, 2019, 2020, 2021])
ax.legend(title='Players', title_fontsize = 13)
plt.show()After running this code, we should obtain a plot similar to the one above.