
AI & Python #3: Concepts You Should Know Before Learning Web Scraping
Make learning web scraping less difficult.


Hi!
We’ve already discussed the importance of data in the AI revolution and have also seen that we can collect this data with a technique known as web scraping.
In this article, we’ll see some concepts you should know to easily learn web scraping. This is what I wish students knew before taking a web scraping course.
Web Scraping is the process of extracting data from a website. Learning web scraping could be as easy as following a tutorial on how libraries like Beautiful Soup or Selenium work; however, you should know some concepts to understand better what these scraping tools do and come up with effective ways to tackle a task.
In this article, I made a list of concepts I wish I knew when learning web scraping. They are either concepts you should understand before learning web scraping or advice to make your code more robust when scraping sites.
1. HTML Basics for Web Scraping
Before you start learning any web scraping library, it’s a good idea to get used to the elements of an HTML document and how web pages are structured.
Let’s take a look at the following HTML code I wrote.
<article type="basic">
<author>John Doe</author>
<title>
<topic area="programming"> Learn Python </topic>
</title>
<date>2021-04-09</date>
</article>This code represents a web with an article titled Learn Python published on 2021–04–09 by John Doe. The code also represents a document with “nodes.” There are element nodes, attribute nodes, and text nodes. Let’s identify each node with the following tree structure.
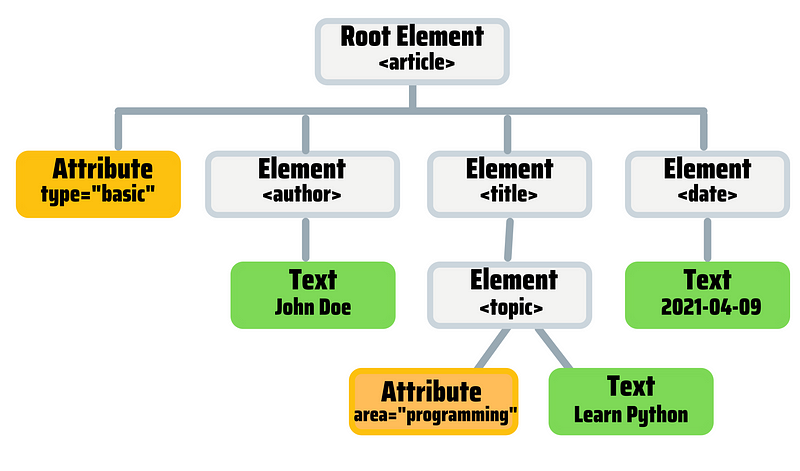
In the tree above, each rectangle represents a node. Also, the tree shows hierarchical relationships between nodes (parent, child, and sibling nodes). This is just a simple example of how elements will be displayed. In reality, a website might have so many nodes that it would be a bit hard to understand.
Let’s identify the relationships between nodes.
