
AI & Python #4: The Easiest Way To Web Scrape with Python
Learning this method won't take you more than 5 minutes.


Hi!
There’s a very easy way to scrape websites with Python. It doesn’t work for all websites out there, but it’s still a simple method that it’s worth learning.
Believe me, this method is so simple that it won’t take you more than five minutes to learn it, so start now!
Did you know that we can easily scrape websites in Python using a library called pandas?
In certain situations, you could avoid building a scraper from scratch with Beautiful Soup, Selenium, or Scrapy and use only pandas to easily extract data from websites.
Pandas is mainly used for data analysis but, in this article, I’ll show you how to use it to extract data from simple websites. This library won’t replace powerful scraping tools, but hey, it can save you a lot of time when scraping simple websites.
Web Scraping in Python with Pandas
With pandas, we can easily extract CSV files uploaded to sites and tables from HTML pages. In case you’re new to pandas, install it using the command below.
pip install pandasExtracting CSV Files
With Pandas, we can read CSV files available on a website. This might seem not so useful when you want to extract 1 or 2 CSV files, but this can save you a lot of time when you need to scrape lots of CSV files.
In this example, we’ll work with the website Football-Data, which provides historical data of football matches for top leagues around the world.
For this example, I’ll scrape CSV files inside the England Football Results section. Here’s how the site looks and the data to scrape:
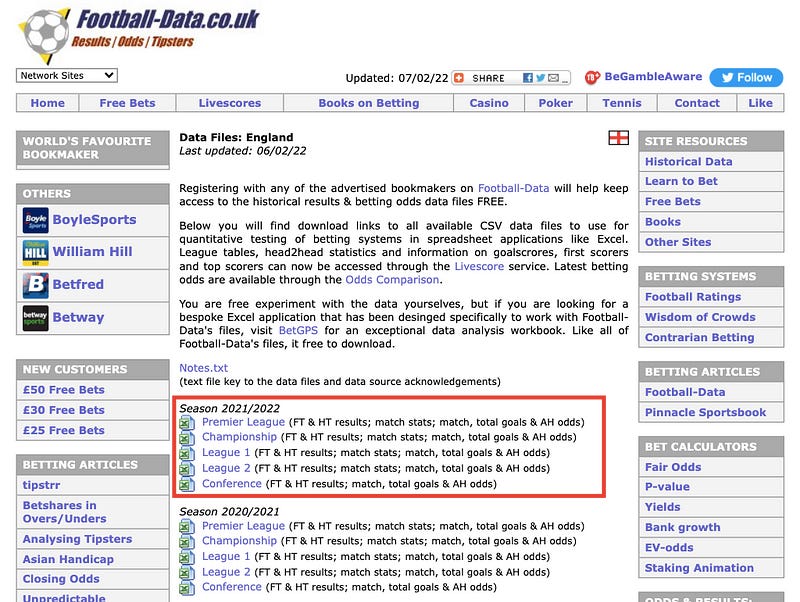
First, let’s scrape the CSV that corresponds to the Premier League season 21/22. Doing this with Pandas is as simple as using the read_csv() method. Inside parentheses, we have to pass in a URL.
To get the URL of any CSV file on the website, we have to hover over them.
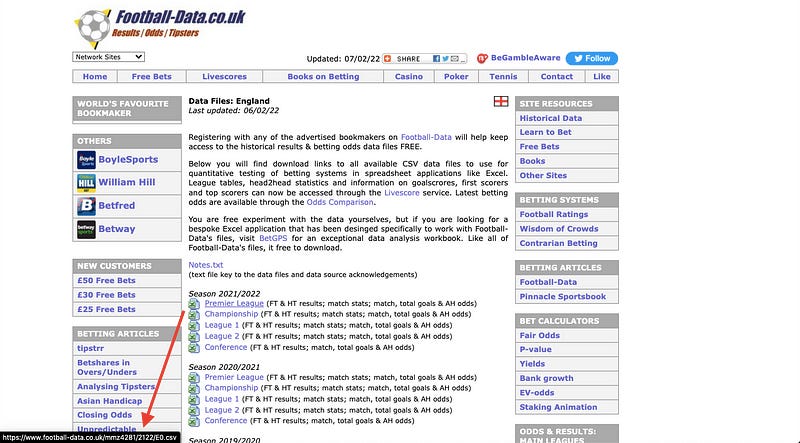
As you can see in the picture above, the link appears in the bottom left corner. We need to copy and put this link into the read_csv() method.
import pandas as pd
pd.read_csv('https://www.football-data.co.uk/mmz4281/2122/E0.csv')After printing the code above, we’ll get the following dataframe.
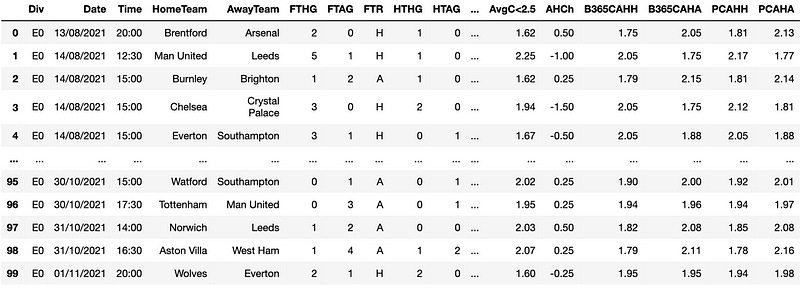
Great! We extracted the data for the Premier League season 21/22.
But what about other competitions listed on the page such as the Championship, League 1, and League 2? We can scrape the CSV file from such competitions and multiple seasons by adding a for loop. Let’s see how to scrape the CSV files from these competitions for season 21/22.
Here are the CSV links to all the English competitions:
- https://www.football-data.co.uk/mmz4281/2122/E0.csv
- https://www.football-data.co.uk/mmz4281/2122/E1.csv
- https://www.football-data.co.uk/mmz4281/2122/E2.csv
- https://www.football-data.co.uk/mmz4281/2122/E3.csvDo you see a pattern in the links? The links have the same root.
root = 'https://www.football-data.co.uk/mmz4281/'And if we split the links by “/” and take a look at the last 2 elements, we’ll see that the first element is the season (2122) while the second is the short name of the leagues (E0, E1, E2, etc)
Let’s put the league names into a list and loop through it:
import pandas as pd
root = 'https://www.football-data.co.uk/mmz4281/'
# creating list of leagues
leagues = ['E0', 'E1', 'E2', 'E3']
# looping through leagues, reading csv and appending it into a list
frames = []
for league in leagues:
df = pd.read_csv(root + "2122" + "/" + league + ".csv")
frames.append(df)That’s it! The frames list contains the dataframes of each league for season 21/22.
Follow the same steps to scrape data for other seasons.
Extracting data from HTML Pages
Pandas can also help us easily scrape tables from simple HTML pages.
Say we want to read all the tables from a Wikipedia article. Some Wikipedia articles contain multiple tables that you can transform into a dataset.
Let’s have a look at one of the tables inside the “List of The Simpsons episodes (seasons 1–20)” on Wikipedia:
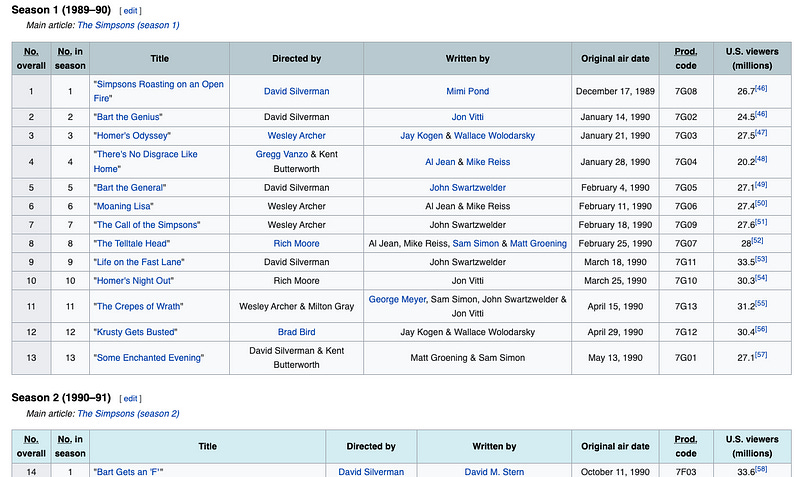
That’s only season 1. You could extract the data inside the 20 seasons on the page by using again the read_html() method.
import pandas as pd
simpsons = pd.read_html('https://en.wikipedia.org/wiki/List_of_The_Simpsons_episodes_(seasons_1%E2%80%9320)')We can get any of the 20 tables by indexing the simpsons list.
# getting the first 5 rows of the table "Season 1"
simpsons[1].head()
That’s it! You’ve just learned how to quickly scrape websites with Python and pandas.