
Claude 3 Beats GPT-4 in Benchmarks: Is That Enough to Switch?
Is it time to cancel your ChatGPT subscription?



Hi!
Before we start with this article, here’s a quick reminder that the early bird discount for my latest course “Modern Data Analyst: SQL, Python & ChatGPT for Data Analysis” ends soon. You can get the course with discount clicking on this link or you can get it for free after becoming an annual paid subscriber here on Substack.
Anthropic’s Claude 3 was just released and it aims to compete with established AI models like GPT-4.
Claude 3 comes in three versions.
Opus (paid version, $20/month)
Sonnet (free version, similar to GPT-3.5)
Haiku
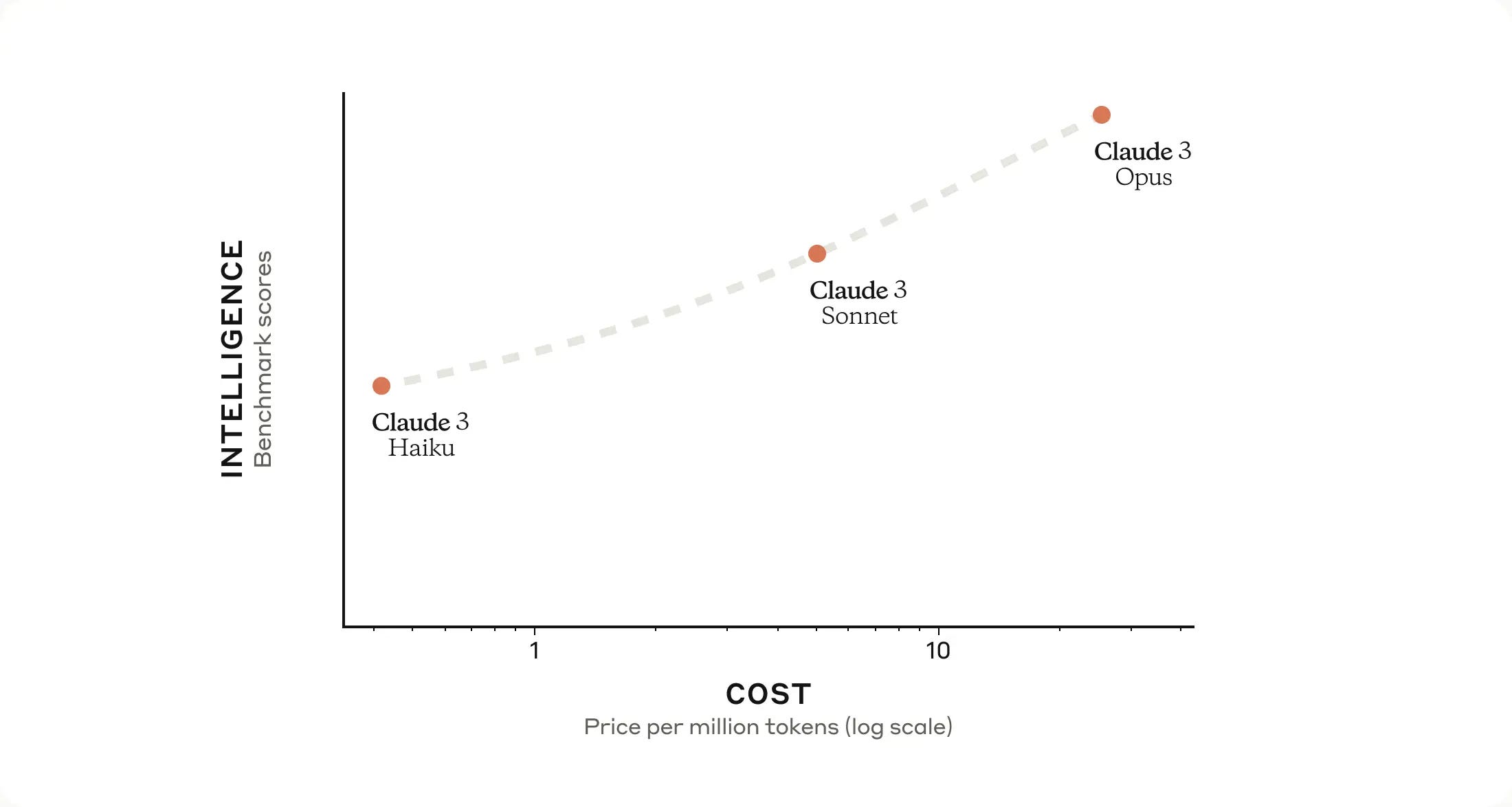
Based on the image above, it's clear that we have the flexibility to choose between performance and cost depending on our needs (Haiku isn't on the market yet though).
When we dive into the benchmarks, it's evident that Claude 3 Opus holds its ground and even edges out the competition (GPT-4, and Gemini Ultra).
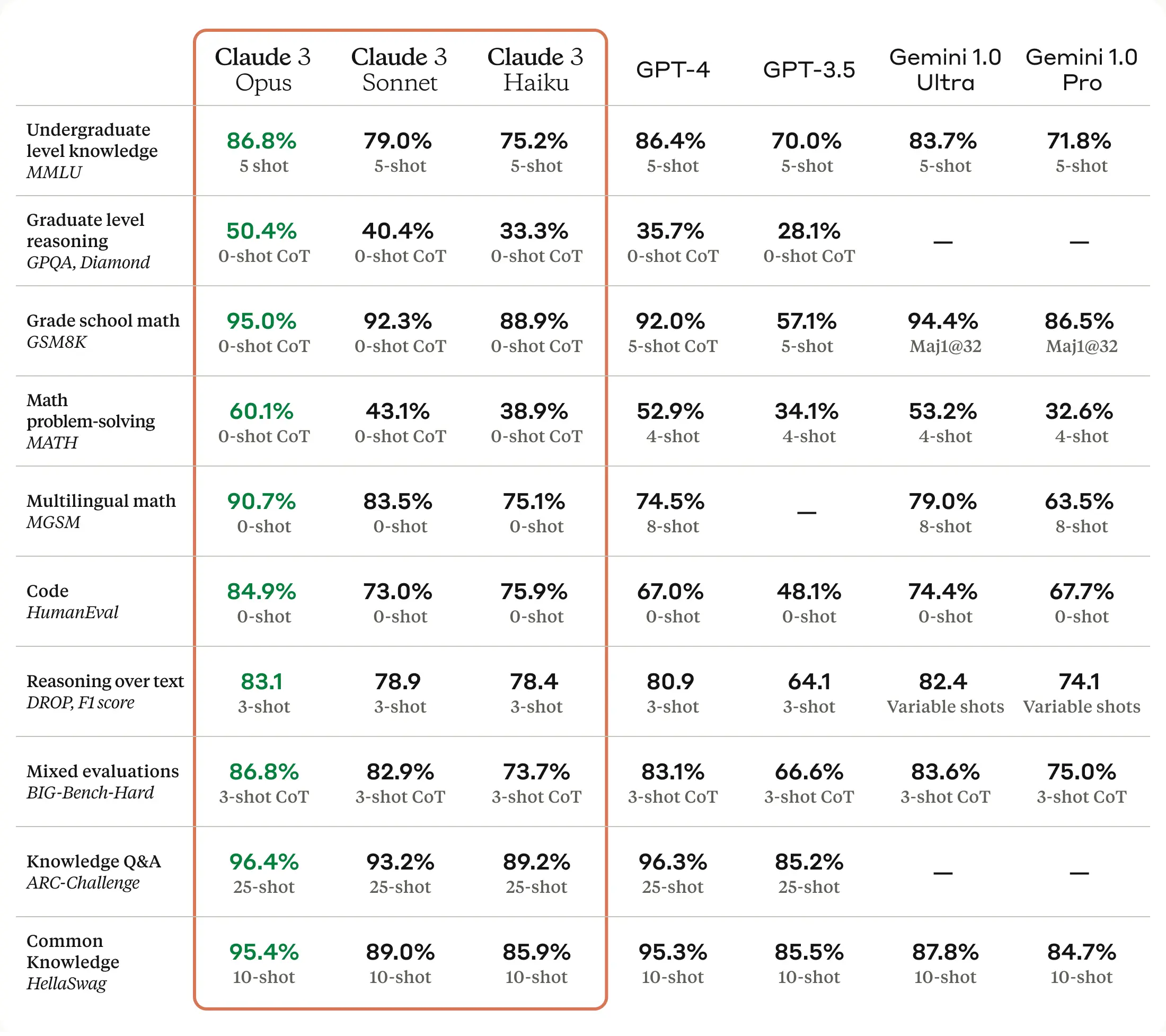
Claude 3 Opus slightly edges out GPT-4 in undergraduate-level knowledge, with a score of 86.8% to 86.4%. But that's not the only area where Claude 3 stands out. In areas such as graduate-level reasoning (GPQA) and grade school math (GSM8K), the differences between Claude 3 Opus and other AI models aren't just noticeable—they're significant.
This hints at Claude 3's ability to tackle and possibly ace tasks where GPT-4 has stumbled, so we’re going to put it to the test. We’ll test Claude 3 Opus and GPT-4 in areas such as creativity, logic, code generation, and vision.
Reasoning
We’ll give both models some exercises to see how good they’re at reasoning.
Complete the series:
2, 4, 8, 16, __, 64
Claude 3 delivers a correct and to-the-point result. It doesn’t dive deep into the details of the value it spits out. You get a simple response from the series right off the bat.

I tried the same prompt a couple of times to see if it generated a more elaborate response, but I got the same to-the-point result.

On the other side, GPT-4 lands on the same solution. Yet, there’s this extra layer that really adds to its appeal for me—it walks us through the sequence used to arrive at the result without me even asking for it.

Claude 3 kept giving short responses to almost all my reasoning questions.
Complete the sequence:
B, D, F, H, J, __

In most reasoning tests I did both models gave good responses, so I’d say it’s a matter of the type of response you’d like to get: Claude 3 Opus’ straightforward responses or GPT-4’s step-by-step explanations.
Code Generation
One thing I like about GPT-4 is its ability to generate code. Now, I'm curious to see if Claude 3 can generate code with fewer or no errors, especially since it supposedly to be more powerful than GPT-4 in this regard.
Let's put it to the test with the next challenge.
Create a function that draws Pascal's Triangle (using only the size of the side)
Long story short, both models generated code that worked. Claude 3 this time even explained how the code worked and what the output would look like.

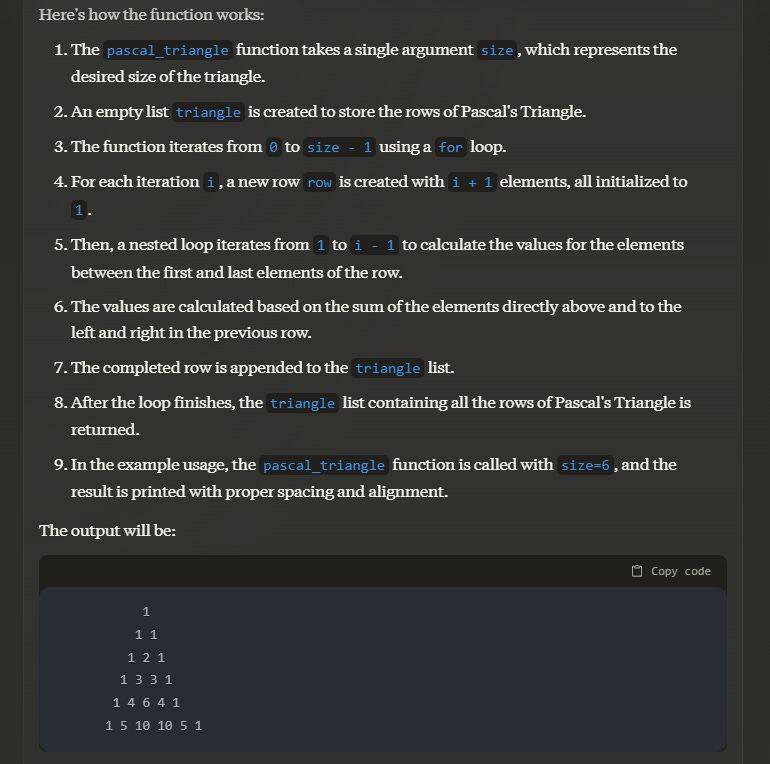
I went the extra mile for this test and calculated the execution time of both scripts. Claude 3 Opus’ code ran in 5.5×10^-5 seconds while GPT-4's code was slower with 2.3×10^-4 seconds. This is a minor detail that might change based on the code you ask both models to generate.
Vision
Let's check out how both models stack up when we put their vision multimodal to the test. For this experiment, we'll use an image showing the ups and downs of Tesla's stock.
What information can you observe and what conclusions could you draw from it?

Claude 3 Opus analyzes the images spotting the company in focus and even nailing the price movements. Offers a neat snapshot, though it leaves me wanting a bit more depth for my liking.

GPT-4 gives the same information as Claude 3 but with more detail and thoroughness.


Overall, both models are good at analyzing images, so I wouldn’t say vision is a factor that would make you switch to Claude 3 if you’re already a GPT-4 user.
Creativity
While this aspect could get a bit subjective, it offers a fresh angle for evaluating the generated responses.
Create an original story that has a robot and a lawyer as characters. This story should not be more than 100 words and must be set in a futuristic context.
Overall, both models hit the mark, though they don’t exactly knock your socks off if you consider originality as a key ingredient.

The narratives from both sides pretty much chase the same goal.

Summary
Overall, Claude 3 holds its own quite well. It generates responses that are as good as GPT-4.
An area where Claude 3 could see improvement is in the quality of its responses. They tend to be overly brief and, at times, a bit too generic for certain situations.
As a subscription, GPT-4 has a slight edge over Claude 3 for exclusive features like Custom Instructions, Code Interpreter, DALL-E 3, and GPTs.
I don't think Claude3 is as capable as Chatgpt in understanding my brand from scratch. My brand was included in the training data for Claude and Claude2, so it's disheartening to start from scratch with an AI that used to be helpful. I'm disappointed with Claude and also with Google Gemini.