
No-Code Tools To Extract Data From Websites
If you don't know how to code, you can still scrape websites. Here's how.


Hi!
In the previous article we’ve seen the importance of data in the AI revolution and today we’ll use the technique companies have been using for years to collect data all over the internet: web scraping.
Now, this article is focused on no-code tools. I believe big companies would not use these tools but have their programmers build scripts to scrape websites, which is more convenient for collecting large amounts of data. If you know the basics of Python and want to acquire this skill, you can redeem my Web Scraping Course in Python for free if you’re an annual paid subscriber here on Substack.
In case you’re not into coding or would like to learn easy ways to collect data, this article is for you.
Web scraping is a skill used for extracting data from websites. Scraping data off websites typically involves learning a programming language like Python and libraries like Selenium or Scrapy; however, even people who don’t know how to code can scrape websites.
That is true! In fact, in this article, I will show you no-code web scraping tools that will make your life easier by extracting the data you want without writing any code.
At the end of the article, we will find out whether you should learn Python’s web scraping libraries or just use one of these tools to scrape a website.
#1 Octoparse
Octoparse makes web scraping easy for anyone. You can quickly scrape web data without coding. You only need to point, click, and extract!
This tool splits the whole scraping process in three steps. First, you have to enter the website URL you’d like to extract data from. Then, you have to click on the target data you wish to extract. Finally, just run the extraction and within a couple of minutes, the data will be ready to use. The data you extract can be stored in a CSV file, Excel, API, or database. Choose the option that fits better for you.
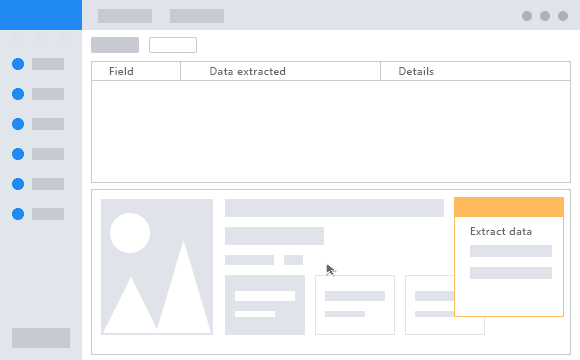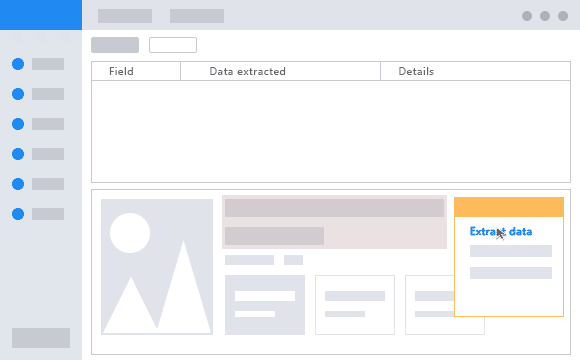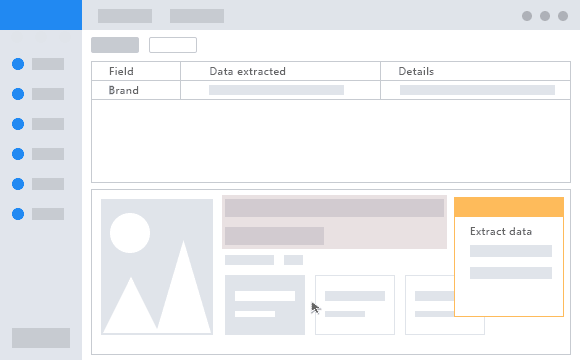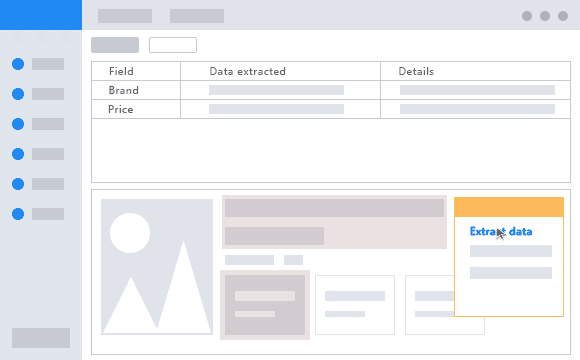
Some advanced features you can accomplish with Octoparse are infinite scrolling, login, drop-down, and deal with AJAX. On top of that, Octoparse offers IP Rotation to prevent IP bans.
Pros of the free version
Unlimited pages per crawl
Unlimited computers
Data retention for 14 days (longest retention among free versions)
10 Crawlers
Cons
In case you want an upgrade, the paid plan starts at $75/month
#2 WebAutomation.io
WebAutomation helps you extract data instantly from any website in minutes without coding using ready-made extractors. The one-click extractors allow you to extract data instantly from 400+ popular websites such as Amazon, Google Maps, eBay, Airbnb, Yelp, and more.
Here’s a demo that shows how it works.
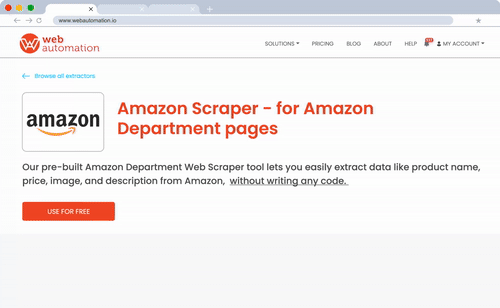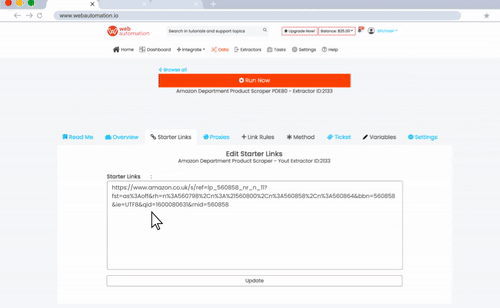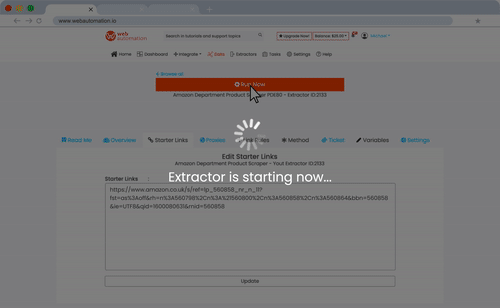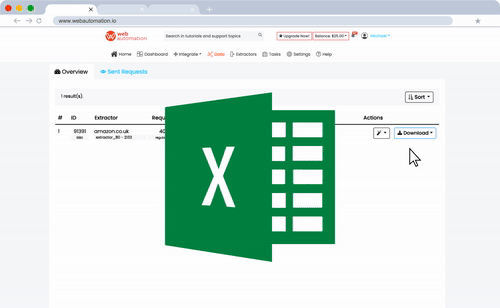
Here’s a list of the pre-built data extractors available. Read the description of any of them to find out what they can and cannot do.
In addition to that, you can also build new extractors with their point-and-click interface. You just have to point and select elements like text/images and then configure your extractor visually. All the data extracted can be exported to a CSV, XLSX, JSON, or XML file. Also, you can transfer data to Shopify, Dropbox, Google Sheets, etc.
Some advanced features it offers are IP rotation, re-captcha solver, and the ability to scrape dynamic JavaScript websites.
Pros of the free version
According to the WebAutomation website, there’s no limitation with the free plan. You will get 10,000 credits that you can use to scrape websites (Regular Request/Plain HTML page: 1 Credit, Browser Request/JavaScript enabled pages: 10 Credits, Advanced Request/reCAPTCHA enabled pages: 100 Credits)
In case you want an upgrade, the paid plan starts at $29/month. It’s the cheapest option among the tools on this list (though check whether the features it offers are enough for you)
Cons of the free version
Data retention of only 7 days on the free plan
Limitations on the use of API and no MySQL integration on the free and cheapest plan
#3 WebScraper.io
WebScraper’s goal is to make web data extraction as simple as possible. Unlike other tools, this is an extension available on Chrome and Firefox. You can configure a scraper by simply pointing and clicking on elements.
WebScraper also allows you to extract data from dynamic websites. It can extract data from sites with multiple levels of navigation and navigate a website on all levels (categories and subcategories, pagination, product pages). The data can be exported to CSV, XLSX, and JSON formats.
Apart from having support for JavaScript-driven websites, it also supports Ajax requests, pagination handlers, and page scrolling. On top of that, it offers a modular selector system, that is, you can build site maps from different types of selectors (e.g., image, text, and table selector)
Pros of the free version
Some advanced features are available on the free version (e.g., dynamic websites and JavaScript execution)
The paid plan starts at $50/month. It’s one of the cheapest options.
Cons of the free version
Local use only
Only CSV export is available on the free version
#4 Parsehub
ParseHub is a powerful web scraping tool that helps you extract data by clicking on the data you need. To do so, first, you have to download its desktop app. Once the app is installed, open it up and choose a site to scrape data from. Then click on the target data to extract it. After this, the data will be collected by their servers and downloaded in JSON, Excel, API, or whatever format you choose.
Some advanced features you can accomplish with Parsehub are getting data from multiple pages, interacting with AJAX, forms, dropdowns, etc.
Pros of the free version
200 pages per run
Data retention for 14 days (longest retention among free versions)
Cons of the free version
5 public projects (the number is ok, but it’s less than Octoparse)
In case you want an upgrade, the paid plan starts at $149/month
Bonus: ChatGPT for web scraping
ChatGPT isn’t a tool meant for collecting large amounts of data, but since this is a newsletter focused on AI and I believe most of you have ChatGPT Plus, I think this ChatGPT plugin I’m about to show you can be useful for web scraping in some scenarios.
The plugin is called Scraper and in the video below I explain in more detail how to work with it.
Now, this plugin doesn’t let you download the data scraped, but I think it’s still useful. I use it to track what other bloggers and YouTubers are publishing on the internet every week.
An alternative to this plugin is this method, but it requires you to save a page as a PDF and then upload it to ChatGPT, which might be tedious if you repeat this process daily.
Are no-code tools better than Python?
In this article, we have seen tools that can help us scrape websites without coding; however, even the best tool will not give you the flexibility or the ability to scrape every website out there.
One of these tools might help you scrape well-known websites with a standard structure, but it would struggle to scrape data off a customized website. This is why learning web scraping in Python is and will remain relevant for a long time.
That said, there are a couple of scenarios where these tools are still useful:
You don’t know how to code and are not interested in learning a programming language like Python.
You belong to a team that can afford the price of such tools (only standard and professional plans cover all features)
Other than that, I’d encourage you to learn how to web scrape with a programming language. It’s not difficult and only requires the basic coding concepts to get started.
Yep, for those of you who want to learn web scrapping using python. You can start with urllib3, beautifulsoup, newspaper3k for scrapping newspaper. those are common libraries that really enough to get started.