
OpenAI Released o3-mini: Best coding model right now (better than DeepSeek R1)
o3-mini is available in ChatGPT for free, plus and pro subscribers

A few days ago, OpenAI released o3-mini and o3-mini-high and it’s available now in ChatGPT and the API.
o3-mini is fast at advanced reasoning, while o3-mini-high is great at coding and logic.
Here’s the amazing part: o3-mini-high’s coding average on LiveBench is 82.74. Other models don't come even close: o1 (69.69) claude 3.5 sonnet (67.13), deepseek-r1 (66.74).
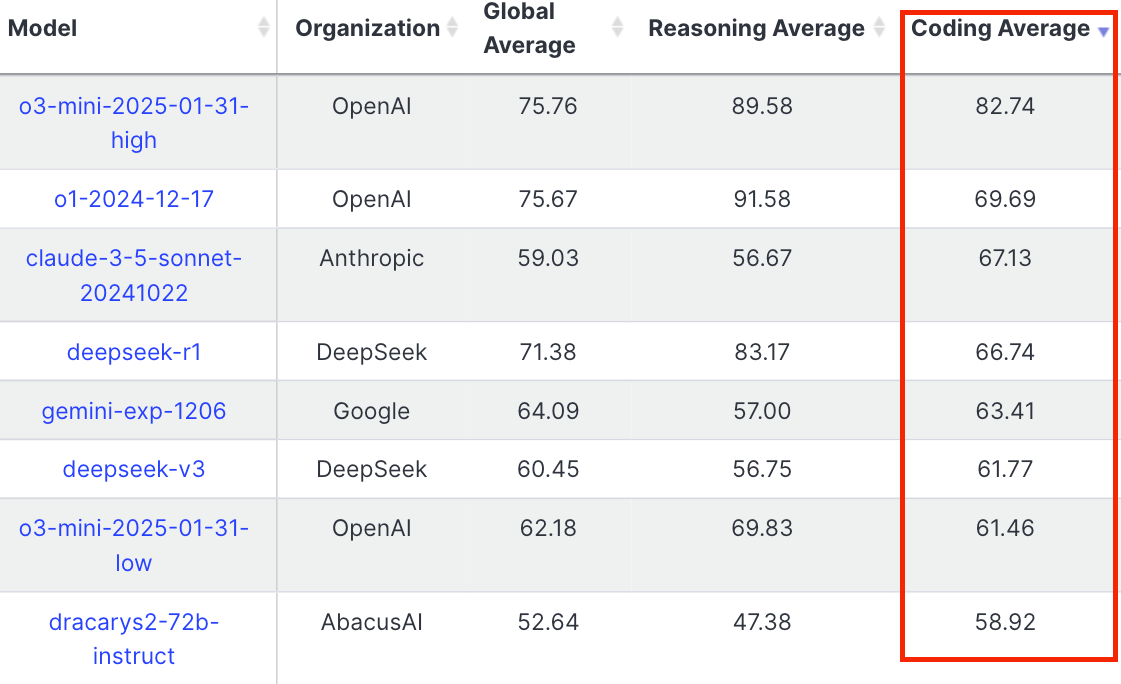
o3-mini-high is the best model for coding right now. Period.
What makes things better is that even free users can try o3-mini in ChatGPT (selecting the Reason button). Plus and Team users have a limit of 150 messages per day with o3-mini, while Pro users have unlimited access to o3-mini and o3-mini-high.
Let’s explore how you can use o3-mini for coding and take a closer look at how well it performs compared to other models
Use cases of o3-mini for coding
The tests show that o3-mini is great at coding. In the examples below, you’ll see that many users could build games, and small apps with one-shot prompts (and a few attempts). This is a good opportunity to start building something with code!
First, here’s a space shooting game that I easily created with Python code thanks to o3-mini. I only gave a few instructions in my prompt, ran the generated code, and got the game quickly.
Here’s another cool game made by an X user that took o3-mini-high 48 seconds.
An X user used o3-mini to create a simple Twitter clone. All in 8 seconds!
Another X user used o3-mini and DeepSeek to write a Python program that shows a ball bouncing inside a spinning hexagon (gravity test). Here’s the result he got.
Just like that, there are many other o3-mini examples showing how good this model is at coding. But don’t take my word for it, let’s see the numbers!
o3-mini is optimized for STEM reasoning
OpenAI o1 model remains their broader general knowledge reasoning model. That said, o3-mini provides a specialized alternative for science, math, and coding. Plus, it reduces the latency of o1-mini.
Here are some insights found from the math evaluation below:
with low reasoning effort, o3-mini achieves comparable performance with o1-mini
with medium reasoning effort, o3-mini matches o1’s performance in math, coding, and science, while delivering faster responses
with high reasoning effort, o3-mini outperforms o1

LiveBench shows slightly different performances in mathematics though.
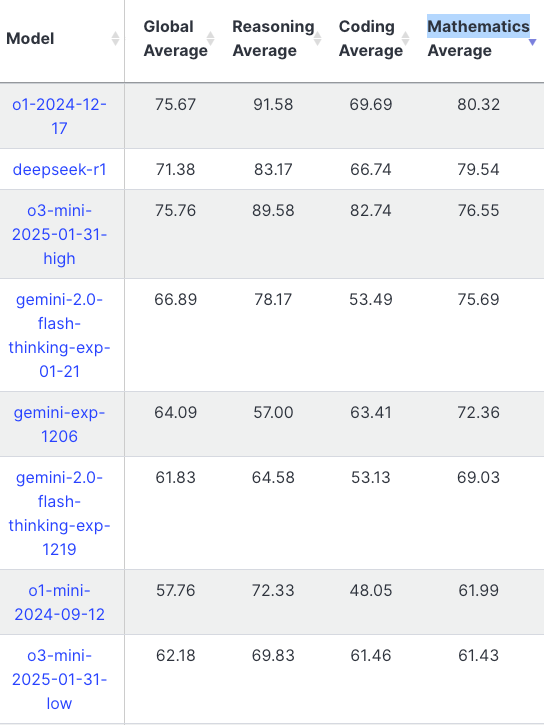
As for coding, LiveBech shows that o3-mini is better than other models (deepseek-r1, o1, claude-3.5-sonnet, etc) even at medium reasoning. At high reasoning, o3-mini extends its lead, achieving significantly stronger performance across key metrics.
In Competition Code, OpenAI o3-mini achieves progressively higher Elo scores with increased reasoning effort.

The same goes for the software engineering test below.

That’s pretty much it! I encourage you to try o3-mini yourself and see whether it outperforms the other models for STEM reasoning.