
OpenAI Releases GPT o1 "Strawberry": First Model With Advanced Reasoning
The AI that thinks like a person


OpenAI has finally launched a brand-new model based on the much-rumored "strawberry" architecture, also referred to as Q*. This is the o1 model, and it’s available starting today for ChatGPT Plus users, but only in the o1-preview and o1-mini versions. We’ll still have to wait a bit longer for the full o1 and o1-ioi versions. These models feature advanced reasoning capabilities, meaning they actually think through and analyze problems before generating a response.
In my opinion, it's surprising how Sam Altman’s team has decided to openly release this model, which has been highly anticipated (since late 2023) by those of us closely following AI developments.
To give you some context, OpenAI envisioned this project in two phases on their ambitious journey toward AGI. The first phase focused on Natural Language, while the second phase is all about Reasoning (which, intuitively, means fewer hallucinations from the AI compared to GPT-4), particularly in areas like math, coding, and science.
Some might think this is just a new version of ChatGPT, but it’s not. This project is something different, which is why it will now be referred to as OpenAI o1, marking a new beginning.
Let’s take a look at some examples of the advantages (or promises) that o1 offers, where GPT-4 might not have performed as well.
1) Coding: Reading every line
It’s interesting to see how this model generates code differently from GPT-4o. The o1-preview actually thinks, meaning it will analyze the entire prompt we provide. In programming, we often give detailed instructions, and with GPT-4o, it tends to overlook or ignore some of them—similar to how we might feel when overwhelmed by too many tasks at once. However, o1 processes all this information slowly and carefully, thoroughly analyzing each requirement.
In the video, they show the following prompt:

You can see there’s a long list of tasks we want to complete to create a visualization that makes an impact, and it produces results like this.
2) Reasoning: Analyzing the surroundings
OpenAI-o1 is aiming to tackle common sense, which is an area where LLMs typically struggle. This means making decisions in complex situations, such as identifying associations between objects and their physical surroundings.
In the video, they present the following prompt:

The response is impressive.

You can clearly follow each step of what o1 is doing. In other words, we can see the logic it's applying based on the context we gave it in the prompt, which involves physical objects and specific scenarios. This is something that GPT-4o finds much more challenging, often leading to the well-known hallucinations.
3) Math: Solving the complex
In the video, they show that o1 can solve medium-difficulty math problems. This enables it to handle tasks like logical sequences, groupings, and trends.
They present the following prompt in the video:

Here are the results:
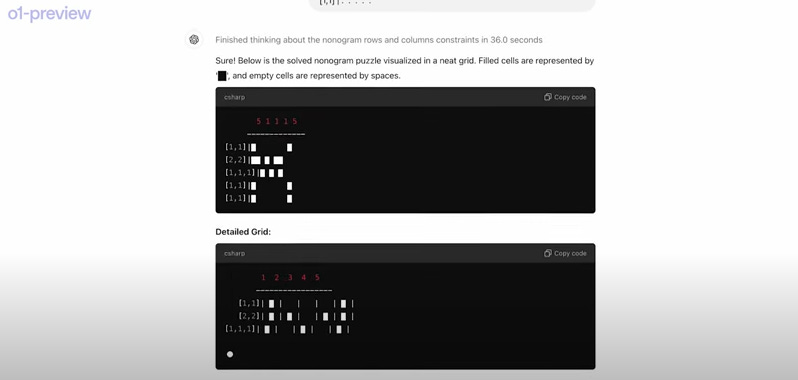
It delivers a perfect solution.
What’s interesting is that logic puzzles like the one shown have often been tricky for models like GPT-4. However, o1 had no problem handling it.
Benchmark Performance and Comparisons
a) Evals
This chart is interesting because it shows how o1 performs compared to GPT-4o and the o1-preview version. While the full o1 model isn’t available yet, it’s encouraging to see metrics with clear differences in areas like math (AIME 2024) and coding (Codeforces). On paper, this looks promising, especially when comparing it to an expert in fields like chemistry, physics, and biology (GPQA Diamond).
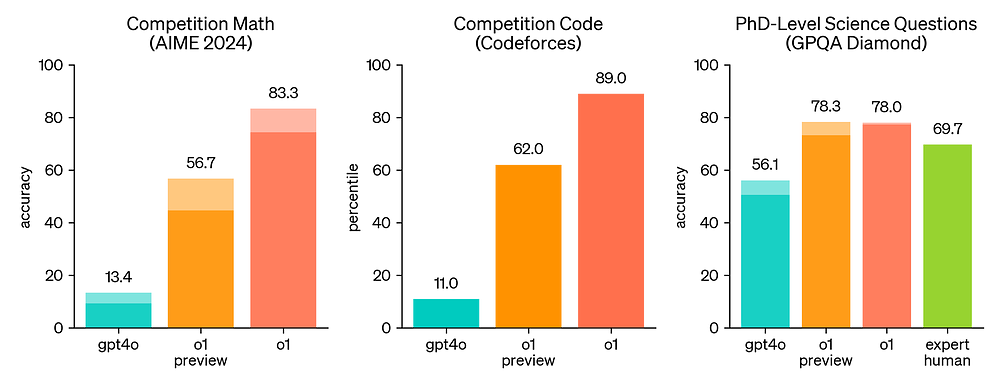
That said, it’s important to keep this in perspective—this doesn’t mean o1 is more capable than a PhD in every sense, just that the model is more competent at solving certain problems you’d expect a PhD to handle.
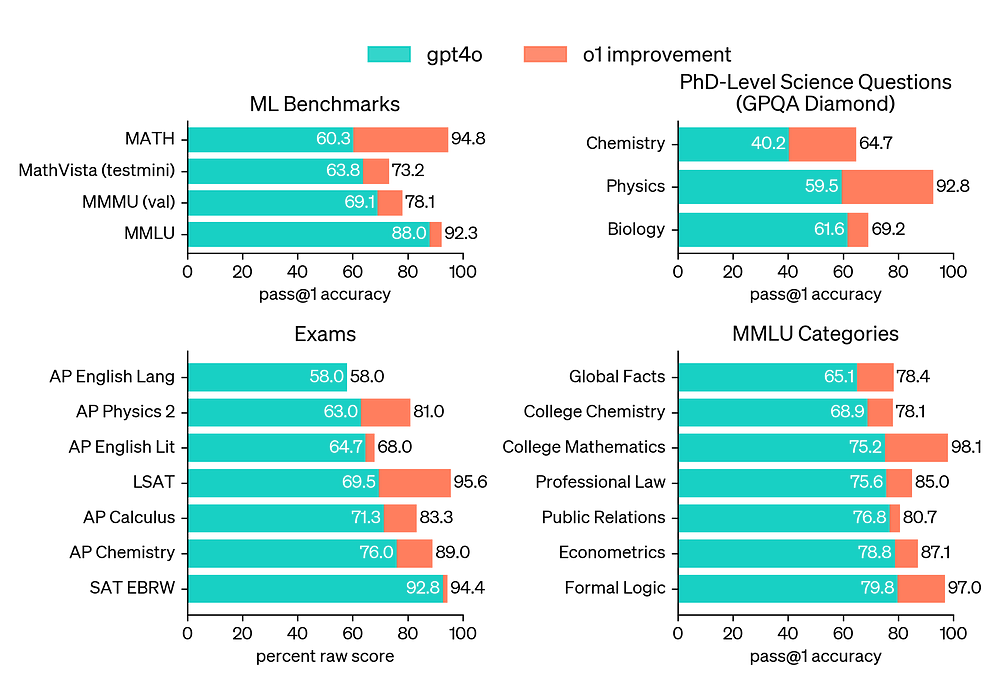
In addition, from the last chart, we can see that o1’s vision modality scored 78.1% in performance, making it competitive with humans in this area.
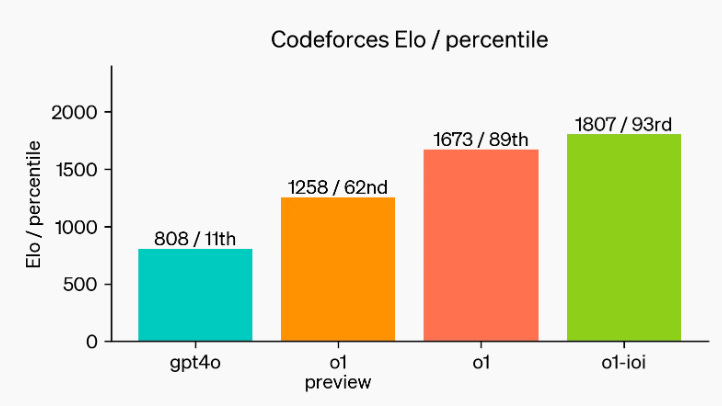
b) Coding
We can see that it outperforms GPT-4o in coding tasks. To put this into perspective, GPT-4o ranked in the 11th percentile among human competitors. In contrast, o1-ioi scored 1807, which places it in the top 7%, outperforming 93% of competitors.
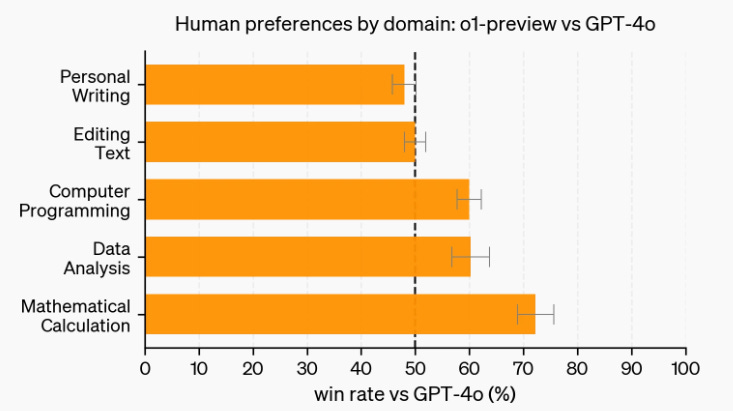
c) Human Preference Evaluation
I find this evaluation interesting because it highlights people's preferences for using o1-preview over GPT-4o. We can see that o1 is favored for tasks like Programming, Data Analysis, and Math, which aligns with the metrics we saw earlier. However, I’m surprised that it still holds its own in natural language tasks.
I've been waiting for this! I'll try OpenAI o1 today 🍓