
Soon, We May No Longer Need Humans to Train AI Models
AZR redefines AI training by eliminating the need for human supervision.


It's hard to believe that an AI could learn just by asking and answering its own questions, without needing human teachers or carefully curated examples.
Until recently, I had never seriously questioned that idea.
But on May 9, 2025, a scientific breakthrough was announced that suggests humans might soon be removed from the equation when it comes to AI development.
A team of researchers introduced a new AI model called Absolute Zero Reasoner (AZR). This system is designed to train itself to reason and solve problems with almost no human-provided data.
In other words, instead of learning from human-written questions, answers, or labels, AZR enters an autonomous training loop where it generates its own problems and figures out how to solve them.
This groundbreaking approach could completely change how we train AI and may mark the beginning of a new era—one where AI systems learn and evolve without direct human oversight.
The Problem with Human Training Data
Modern AI systems, especially large language models, rely heavily on data curated by humans. From millions of Wikipedia articles to expert-written math solutions, these models typically improve by learning from large volumes of human-generated examples.
But this approach is starting to show its limits.
Researchers point out that collecting massive, high-quality datasets is becoming increasingly unsustainable, especially as AI models grow larger and demand more data.
We're essentially running out of carefully selected texts and problems that are useful for training the next generation of intelligent systems. On top of that, there’s a fundamental limitation: humans can only create tasks we already know how to solve.
As one research paper puts it, depending exclusively on human-designed tasks "risks imposing constraints on [AI's] capacity for autonomous learning and growth."
In other words, if we hope to build AI that eventually exceeds human intelligence, we can’t keep feeding it only the problems we already understand.
That’s where the Absolute Zero paradigm comes in.
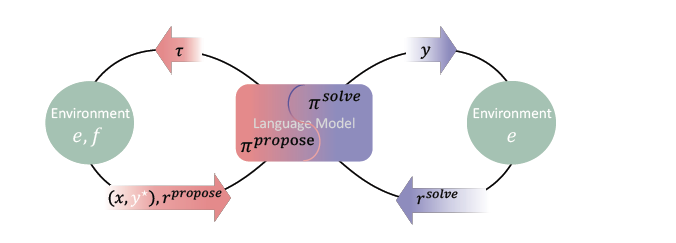
The idea is radically simple: don’t use any human data. No more handpicked question-and-answer pairs or labeled examples. Instead, let the AI generate its own training curriculum through trial and error.
This approach is inspired by earlier successes in self-play systems. One well-known example is DeepMind’s AlphaZero, which learned to master chess and Go entirely by playing against itself, with no access to human game records.
Just like AlphaZero only needed the rules of the game and a basic win-or-lose signal, Absolute Zero provides an AI model with a minimal environment and verifiable feedback, and tells it to learn on its own.
The environment itself determines whether the AI's response is correct or not. No human is involved in providing examples or correcting mistakes.
Getting to Know the Absolute Zero Reasoner (AZR)
The Absolute Zero Reasoner, or AZR, is the first real-world implementation of a training method that doesn’t rely on any human-provided data.
You can think of AZR as an eager student without a teacher, so it becomes its own.
Throughout the training process, AZR continuously creates new problems and attempts to solve them by itself. The only external help comes from a code execution environment, which works like an automated grader to check whether its solutions are correct.
When a solution is correct, AZR receives positive feedback. If it’s wrong, it gets no reward. Over time, it learns from this feedback and steadily improves its problem-solving abilities, all without ever seeing a human-written example or explanation.
So how does AZR know what kinds of problems to create in the first place?
This is where the "propose and solve" loop comes in. AZR plays a dual role.

In the first role, it acts as the Proposer, generating new tasks or questions that it will later attempt to solve. It’s rewarded for creating problems that strike a balance—not too easy, not impossibly hard. If a task is solved too quickly or can’t be solved at all, the proposer doesn’t earn any points. This motivates the system to challenge itself just enough to keep growing, gradually pushing its own limits.
In the second role, it becomes the Solver, where it switches focus and works on solving the problem it just created. It tries different approaches and produces a solution.
The same environment—the Python-based execution system—checks the answer. AZR receives a binary reward: one point for a correct solution, zero for an incorrect one. This cycle continues automatically.
AZR generates new problems, solves them, gets feedback, and updates its internal model to improve both how it asks questions and how it answers them.
As its skills grow, the problems naturally become more complex.
The researchers started AZR off with only the simplest examples. From there, it took off. Before long, it was inventing and solving advanced coding and math problems that no human had ever provided.
Types of Reasoning: Induction, Deduction, and Abduction
To help AZR develop a well-rounded reasoning ability, researchers designed it to practice three complementary problem-solving methods. These methods correspond to the three classic modes of reasoning, adapted into coding tasks.
The first is deductive reasoning, which involves moving forward logically from given information. In this task, AZR is provided with a piece of code and an input, and it must figure out the correct output. This is like mentally running a program or following a recipe to see what it produces. It tests the model’s ability to apply logical steps accurately and consistently.
The second is abductive reasoning, which works backward from a known result. AZR is given a program and a desired output, and it must infer a plausible input that could produce that output. It’s a bit like solving a mystery where you know the ending and the method, but need to figure out the beginning. This mirrors trial-and-error thinking or reasoning from effects to causes.
The third is inductive reasoning, which focuses on recognizing and generalizing patterns. AZR is shown several input-output pairs and must figure out the code that could generate all of them. In other words, it has to write a program based on examples. This tests its ability to spot patterns and generalize rules from limited information.
By rotating through these three modes, AZR learns to tackle different types of reasoning challenges. Deduction helps it follow logical sequences, abduction encourages reverse thinking and creativity, and induction builds its ability to generalize from patterns.
One of the key aspects of this system is that AZR doesn’t treat these modes separately. It can use a solution from one type of task to generate new challenges in another. For instance, a program it solved during a deduction task could be repurposed to create a new induction problem.
This kind of interaction between modes helps ensure that AZR isn’t just memorizing solutions. Instead, it’s building a flexible way of thinking that can adapt to new and unfamiliar problems.
How AZR Differs from Traditional AI Training
AZR’s self-training approach is a major shift from how AI models have traditionally been trained.
There are two main methods typically used to improve a model’s reasoning ability.
The first is supervised learning, where the model is fed a large number of solved examples. These usually include questions with correct answers, and often even detailed, step-by-step solutions. This is the standard approach behind many math solvers and coding assistants.
The problem is that it depends on massive datasets of curated problems and answers, all of which must be created, labeled, or verified by humans.
The second method is reinforcement learning, where instead of being shown explicit solutions, the model receives rewards for producing correct answers or for displaying certain behaviors.
A common variant is RLHF (Reinforcement Learning with Human Feedback), where human preferences are used to guide the learning process. This is one of the techniques used to fine-tune models like ChatGPT. Another version is RLVR (Reinforcement Learning with Verifiable Rewards), where automated systems provide rewards based on whether the model's outputs are correct.
Both of these methods still rely on a predefined set of tasks or questions. Even if the model isn't told how to solve them, the tasks still come from people.
What sets AZR apart is that it eliminates the need for a human-designed training set entirely.
This is similar in spirit to what AlphaZero achieved in board games. AlphaZero didn’t need databases of chess matches played by grandmasters. It simply played millions of games against itself and learned from the experience.
AZR takes a similar approach but applies it to open-ended reasoning rather than structured games. The challenge here is that, unlike chess, reasoning tasks don’t always have clear rules or win conditions. To address this, AZR uses a code execution environment as its framework for learning. It treats the coding environment as both a testing ground and a judge. Any task can be framed as "write a program that does X," and the program can be run to check if the output matches the expected result.
This setup allows AZR to engage in a kind of open-ended "reasoning game" with itself. Success is always clearly defined by whether the output is correct.
So what’s the outcome?
AZR was able to learn skills that normally require large amounts of human input. In some cases, it even outperformed models that had the benefit of human-generated data.
It’s a strong proof of concept that an AI can learn to reason without needing a teacher—guided only by whether its own answers make sense.
Reaching superhuman reasoning may still be a goal for the future, but AZR has already proven that AI can take meaningful steps forward in areas we used to think required human supervision.
State-of-the-Art Results Without Human Data
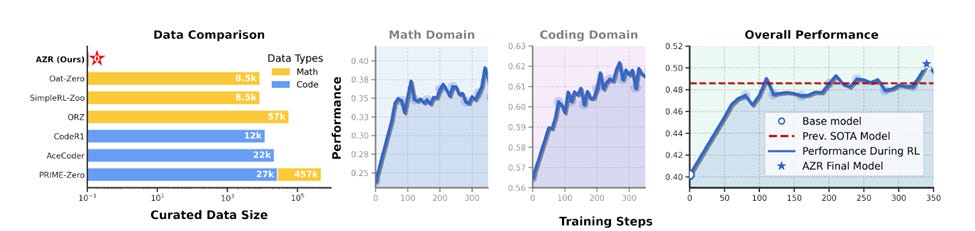
The results speak for themselves. Even though AZR was never exposed to a single human-written training example, it managed to match—and in some cases surpass—models that were trained on large volumes of human-curated data.
In a benchmark evaluation made up of coding challenges and math problems, AZR set a new high score for coding tasks and delivered competitive performance in mathematics.

One version of AZR, built on a 7-billion-parameter code model, solved about 83.5% of the coding tasks. That slightly outperformed the previous best model, which had been fine-tuned using thousands of human-created examples. AZR’s overall score across both math and coding was approximately 50.4, beating the previous top reasoning model.
That might seem like a small lead, but it’s important to keep in mind that every other model in the comparison had the unfair advantage of extensive human-labeled training data. AZR had none.
What’s especially striking is AZR’s ability to generalize. Since it wasn’t trained on any specific problem formats or examples, everything it encountered during evaluation was essentially new.
And yet, it performed remarkably well.
Training on code problems gave AZR strong enough reasoning skills that it also did better on pure math questions. According to the researchers, AZR improved the accuracy of its base model on math tasks by 10 to 15 percentage points. In contrast, a similar model trained with human-labeled data showed little to no improvement in math.
In short, AZR learned how to think in a way that transfers. That kind of generalization is often considered a key goal in AI research. The results support a hopeful idea: if we can teach an AI to truly reason, it can apply that ability well beyond the tasks it’s trained on.
