Behind AI #3: Vector Databases - Taking Data Revolution to The Next Level
Here's how AI-centric vector databases are gaining their place in modern software stacks.


In the previous article of our Behind AI series, we explained in plain English what databases are and compared the top DBMS. Today, we’ll focus on a type of database that has become increasingly important in AI: vector databases.
The internet contains a huge amount of data in different forms. In the past, this data was mostly structured, but as the internet grew, unstructured data such as photos, audio, text, and video files became more common.
Analysts estimate that 80-90% of any organization’s data is unstructured, so how can we deal with this unstructured data?
Traditional relational databases and NoSQL databases struggle to analyze unstructured data especially when it comes to doing it in real-time. Here’s when vector databases can help. They were built to manage massive embeddings vectors converted from unstructured data.
In this article, we’ll learn more about vector databases, how they can help us manage unstructured data, and the solutions they offer.
Vector Databases vs Traditional Databases
Relational databases store items with pre-defined relationships between them. These databases typically organize data in tables with columns and rows. This is known as structured data and is generally easy to search and analyze. In contrast, unstructured data is more complex and requires more work to understand.
Machine learning and deep learning models can help us understand this unstructured data by transforming it into vector embeddings. These embeddings are high dimensional vectors that describe complex data as numerical values in different dimensions.
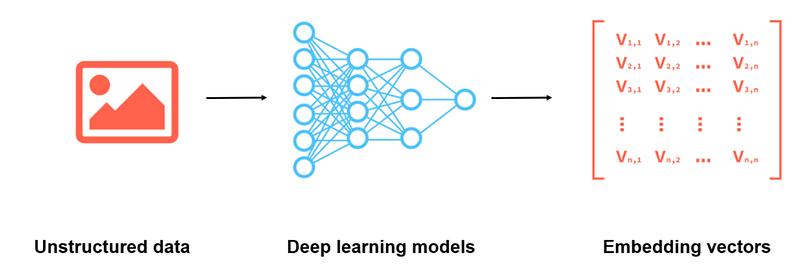
Vector databases are designed for search and data mining.
This search involves querying data as we’d do with a relational database. However, a relational database retrieves results that are an exact match, while a vector database offers more complex search capabilities.
One of the types of search that vector databases excel at is similarity search (aka vector search). Similarity search consists in finding the most similar item to the one we’re looking for. This task is called nearest-neighbor search because the similar items we get are actually near-neighbor matches. This list of items wouldn’t exist if we weren’t performing a similarity search.
To sum it up, traditional databases return results that are an exact match, while a vector database returns near-neighbor matches. In addition to that, vector databases offer good speed, accuracy, and flexibility.
This is great for product search. Say we want to buy black Nike shoes, so we go to our favorite online store and search “black Nike shoes.” If the search engine was built with similarity search functionalities, we’ll get similar items, in case there aren’t any black Nike shoes in the inventory.
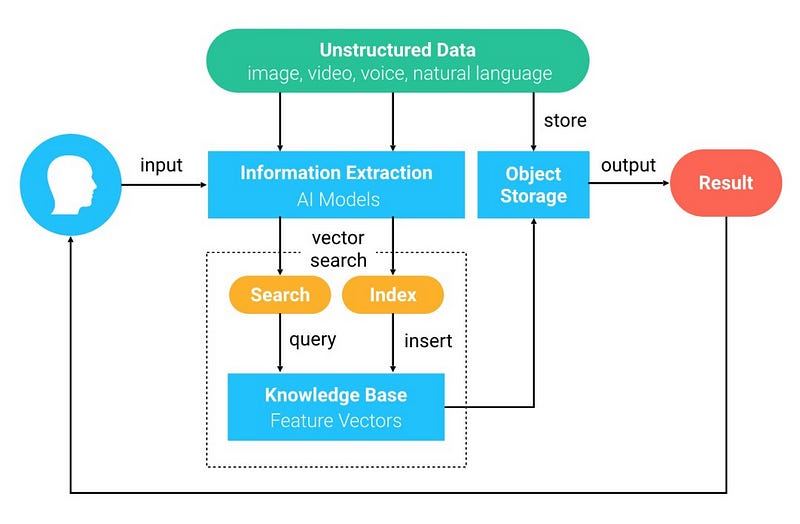
This is just one of the applications that vector databases have. Let’s see some common use cases.
Vector Databases Use Cases
Recommendation Engines
Recommendation systems are everywhere. They’re used to suggest items similar to past videos, movies, purchases, and more.
Vector databases are great for building recommender systems. Its similarity search functionality makes vector databases a good option for suggesting relevant items to users.
We could use vector databases to build a recommender system that would suggest movies that a user might like based on the user’s historical movie rating data. We could also build a system that recommends products based on past purchases a customer made.
Semantic Search
Semantic search is a data searching technique that not only allows us to find keywords but seeks to understand natural language as a person would do.
How does it do that? It puts our search query into context.
We can use vector databases to index vector embeddings from NLP models in order to understand the context of the text. This provides more accurate search results.
If you remember all the things you search on Google, you’ll realize that we often use natural language in our queries. Semantic search is then necessary for a search engine to provide relevant results.
Similarity Search
Unstructured data such as images, video, and audio are hard to classify in relational databases.
There are some workarounds to deal with this using relational databases, but different people would use different criteria, which makes this more complicated.
In contrast, vector databases can analyze large-scale data in real-time. They’re behind image search technologies such as autonomous cars that are able to recognize objects and phones that can recognize the face of a user. They’re also present in audio search. This helps our devices identify the name of a song or a user’s voice.
A case study of a vector database
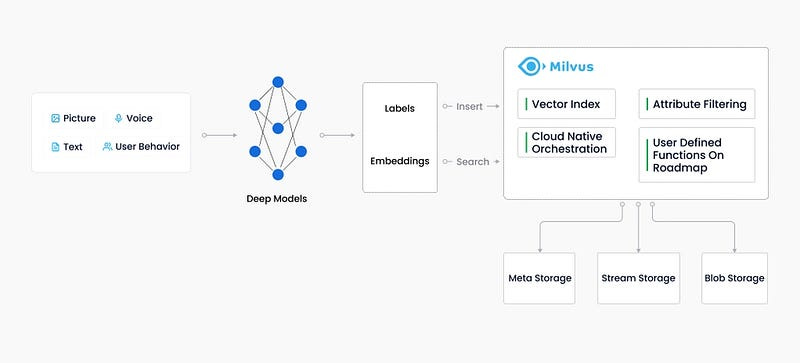
There is an emerging market for vector databases out there. Let’s take Milvus as an example and look at its features and advantages.
Milvus is an open-source vector database that was created with the purpose of storing, indexing, and managing embedding vectors generated by machine learning models.
Unlike relational databases that handle structured data using a pre-defined pattern, Milvus can handle embedding vectors converted from unstructured data.
Here’s why Milvus is a good option:
It offers high performance when conducting vector search on massive datasets.
Cloud scalability and high reliability even in the event of a disruption.
Hybrid search achieved by pairing scalar filtering with vector similarity search.
Here’s the Milvus workflow.