
GPT-5 Prompting Techniques
Here's how to make the most out of GPT-5


Most users are not fully tapping into GPT-5’s potential.
Why? Because it’s a new model (different from previous ones) that has changed how ChatGPT works!
I’ve spent many hours studying OpenAI’s GPT-5 prompting guide to better understand how to make the most out of the model through both the ChatGPT web app and OpenAI Playground. In this guide, I’ll explain OpenAI’s prompting recommendations in plain English, avoiding most of the technical jargon found in the official guide.
Table of content:
- Technique #1: How to quickly optimize a prompt
- Technique #2: Improve instruction following
- Technique #3: Make chatgpt less chatty (verbosity control)
- Resources to master GPT-5 (Updated Oct 2025)
- Advanced Technique #1
- Advanced Technique #2#1 Prompt optimizer
There are two simple ways to optimize a prompt
Option #1: OpenAI Prompt Optimizer
OpenAI has a GPT-5 prompt optimizer available in Playground. Playground is a platform designed for advanced users to choose different models, tweak model parameters, and more (in fact, we’ll use Playground from tip #3).
One of the cool things we can find in Playground is the prompt optimizer.
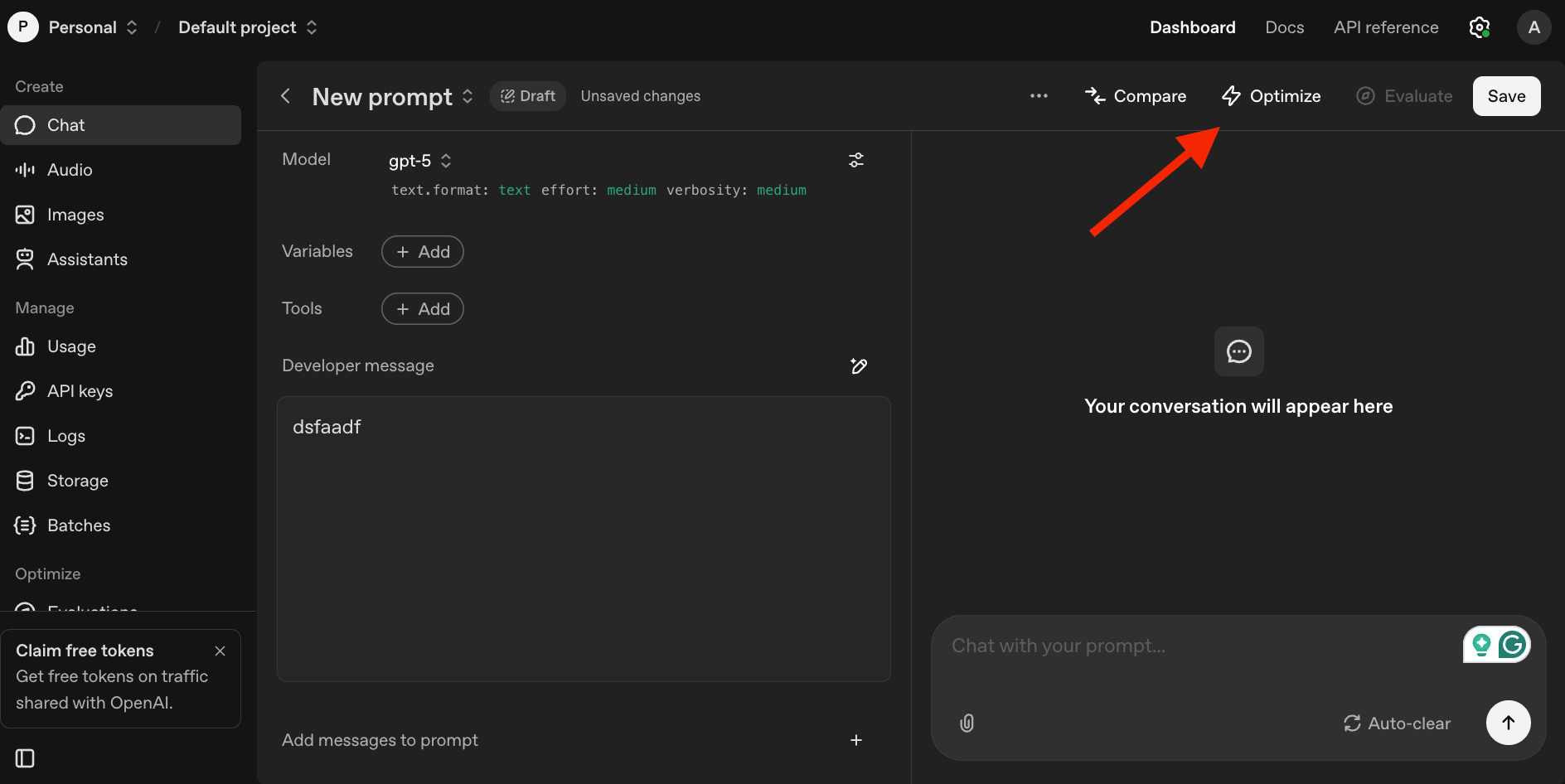
To use the prompt optimizer, click here and log in with your ChatGPT account. Then type or paste your prompt and click on “Optimize” to get feedback. Once your prompt is optimized, the tool will highlight the changes in blue, and the notes icons on the right will provide the reasoning behind those changes.
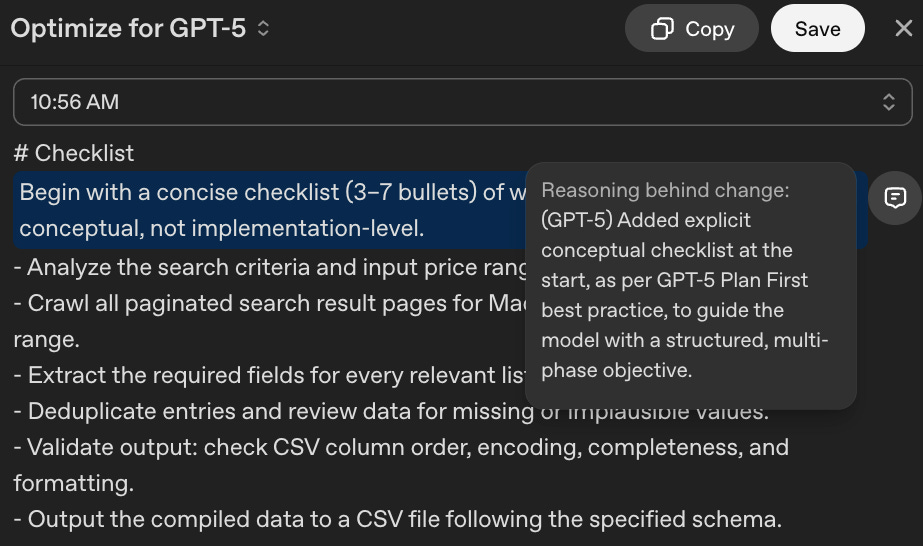
The tool is useful, but it’s still necessary to learn the additional prompting tips in this guide to understand the changes it makes and to recognize when those changes are necessary.
Option #2: With a ChatGPT prompt
In this article, I shared a prompt template that you can use in ChatGPT (or other AIs) to optimize your prompts. The article is split into two parts. Make sure you follow the steps in both to optimize your prompt properly.
In the next sections, we’ll see some prompt techniques and resources to master GPT-5 (that you won’t find anywhere else). Also, I’ve included copy-and-paste prompts so you can put these techniques into practice.